又到了期末的自評時間了,也趁這個時間好好的來檢視自己學習的成果和自我檢討。
想當初自己對於這門課其實還有點興趣,因為專研的老師剛好有做這方面的研究,所以在平常的MEETING中也聽到了一些概念。但是上了課之後發現好像有些不同,老師所講的是如何將資訊藏到影像中 (資訊隱藏),而我自己平常所聽到的其實是較偏視覺密碼這一方面,不過這些其實都是後來的事了。
雖然有些不同,但本質上應該是一樣的理論,都是將資訊隱藏到圖片中,所以還是決定繼續留下來。縱觀這一學期所學到的東西,雖然講的不是非常多,但是老師講解的部分也確實的吸收了,例如在 3/29的課程中,講到了如何利用調色盤將欲隱藏的資料存進其中一點,其中也提到了將調色盤更改他的索引值來藏影像,以及LSB和MSB的一些探討;
4/19 則是在討論GIF檔中的雜點問題,先將新的GIF排序後,可得到兩兩一組相同系列的顏色,在記取新的index值,傳送時傳送原來的調色盤,再依照新的index直塞入,借此來消除雜點,之後還有比較PSNR和RMS兩圖的相似度,PSNR越大則越相似,而RMS則越小越好。
5/10 講到了將KEY經過PRNG(假亂數產生器)處理後得到新的座標點,然後將此點找到他在調色盤中的index值,找到後先算他的parity值,若與要藏的資訊的值相同則不變。但如果P不同,則找相近的顏色,且P要相同。舉例來說假如要藏1,假使依index找到的P為0,則找第一接近的顏色,若第一接近的P仍為0,則在找第二接近的,直到P=1為止。
上述的這些是我的小筆記本中的一些摘錄,而在期中考後,因為專研在星期四的關係再加上自己也常常睡過頭,雖然說的很多,但仍然沒辦法掩蓋自己沒上課以及寫部落格的事實。或許自己是屬於需要一點壓力的人吧......我覺得老師的教學很好,也都能學到一些東西,但是像我自己可能就沒辦法適應這種自由的風氣,所以需要一些小小的壓力來讓自己讀書。
說了一大堆,想必老師也看得累了,我就在這邊做個結束,關於這門課的自評分數,我給我自己60分。
93360621 資工三乙 蔡峻宇
2007年6月21日 星期四
感想與自評
很快的一學期又結束了
這堂課最讓我有映象的不是課堂內容
反而是老師的教學方式
老師的教學方式讓我覺得這才是大學上課該有的氣氛
上課的互動不用說,老師還會帶領我們去思考與解決問題
不像其他大部分的課程都是施與受的死板上課方式
我覺得許多大學教授的教學方式都承襲了高中的那種填鴨式教學法
那種方法我覺得是抹殺學生們創作思考的能力的原因
再來是課程內容
從一開始的S-Tool到最後的JEPG原理
其實只是大致了解他們的主要概念而已,
主要是有太多次課沒有跟大家一起討論
內容都是閱讀部落格而來的
自己也在檢討自己的缺課次數....
雖說不能推託,但上課當天下午有專研地獄等著我(抖
所以常犧牲上課時間換取指導教授的一句OK(大抖
<囧>"
這裡就不得不佩服老師的BLOG了
讓我即使沒出席課堂也能知道當天大家在討論什麼和要做些什麼
雖然老師說過這BLOG會讓學生偷懶不來上課
但是這BLOG卻是讓學生了解整個課程的大綱架構,我覺得是利多於弊,所以是支持這BLOG系統
至於老師有提到說本系學生都懶於撰寫BLOG,我倒是覺得可以像外科系一樣實施互評系統
一來可以訓練那些懶於撰寫BLOG的人盡量發表自己的看法
二來大家也會勤於討論課程內容,而不是BLOG寫一寫就了事
說這麼多當然只是我的一些些感想罷了,如果能給老師當做參考那再好也不過
其實自己也很清楚自己花了多少心力在這課程上
所以自己給自己的成績是60分的及格邊緣
感謝老師這一學期的指導
這堂課最讓我有映象的不是課堂內容
反而是老師的教學方式
老師的教學方式讓我覺得這才是大學上課該有的氣氛
上課的互動不用說,老師還會帶領我們去思考與解決問題
不像其他大部分的課程都是施與受的死板上課方式
我覺得許多大學教授的教學方式都承襲了高中的那種填鴨式教學法
那種方法我覺得是抹殺學生們創作思考的能力的原因
再來是課程內容
從一開始的S-Tool到最後的JEPG原理
其實只是大致了解他們的主要概念而已,
主要是有太多次課沒有跟大家一起討論
內容都是閱讀部落格而來的
自己也在檢討自己的缺課次數....
雖說不能推託,但上課當天下午有專研地獄等著我(抖
所以常犧牲上課時間換取指導教授的一句OK(大抖
<囧>"
這裡就不得不佩服老師的BLOG了
讓我即使沒出席課堂也能知道當天大家在討論什麼和要做些什麼
雖然老師說過這BLOG會讓學生偷懶不來上課
但是這BLOG卻是讓學生了解整個課程的大綱架構,我覺得是利多於弊,所以是支持這BLOG系統
至於老師有提到說本系學生都懶於撰寫BLOG,我倒是覺得可以像外科系一樣實施互評系統
一來可以訓練那些懶於撰寫BLOG的人盡量發表自己的看法
二來大家也會勤於討論課程內容,而不是BLOG寫一寫就了事
說這麼多當然只是我的一些些感想罷了,如果能給老師當做參考那再好也不過
其實自己也很清楚自己花了多少心力在這課程上
所以自己給自己的成績是60分的及格邊緣
感謝老師這一學期的指導
[Ending]課程回顧 - 自評
這學期的課程已經到尾聲
原本修這門課只是想讓自己能學多點知識
後來我也覺得在這堂課學了不少東西
像是怎麼怎麼隱藏資訊阿
隱藏資訊的的原理
另外也實際利用軟體去把想要隱藏的資訊藏在圖片裡
然後老師也讓我們看了一篇paper
這篇paper使我更了解 原來技術能越來越好
並且也知道EZ-stego的做法和新的方法
之後老師讓我們去做投影片來報告此paper的重點
自己的毛病還是在 容易緊張 或許是準備不夠充分
在後來可能因為畢業了 心情也放鬆了
接下來的課都睡過頭沒有去
知道後來講的是jepg的相關原理 不禁感到懊惱
關於自評的部分
我想自己也很少去發表文章
跟老師的互動雖然有些反應
我想還是不夠的 加上後來的課沒去(連今天也沒有)
這大概是我上大學以來缺最多課的第2次(第1次也是這學期)
我頂多只能給自己60分
原本修這門課只是想讓自己能學多點知識
後來我也覺得在這堂課學了不少東西
像是怎麼怎麼隱藏資訊阿
隱藏資訊的的原理
另外也實際利用軟體去把想要隱藏的資訊藏在圖片裡
然後老師也讓我們看了一篇paper
這篇paper使我更了解 原來技術能越來越好
並且也知道EZ-stego的做法和新的方法
之後老師讓我們去做投影片來報告此paper的重點
自己的毛病還是在 容易緊張 或許是準備不夠充分
在後來可能因為畢業了 心情也放鬆了
接下來的課都睡過頭沒有去
知道後來講的是jepg的相關原理 不禁感到懊惱
關於自評的部分
我想自己也很少去發表文章
跟老師的互動雖然有些反應
我想還是不夠的 加上後來的課沒去(連今天也沒有)
這大概是我上大學以來缺最多課的第2次(第1次也是這學期)
我頂多只能給自己60分
[Ending]課程回顧 - 自評
第一次自評感覺還滿妙的整體上
雖然幾乎都有來上課
但上課沒說很進入狀況
又缺於和其他同學以及老師討論
在BLOG的貼文上,又沒勤找資料
就得不到什麼感觸寫出文章來
全部包含這篇文章,全部也才貼出五篇 數量真的還滿少的
上課採討論方式
可以增加很多師生互動
觀念比較不會被全部被牽的走
如果有認真思考一下 就會比較有自己想法
所以大概只打給自己65分
雖然幾乎都有來上課
但上課沒說很進入狀況
又缺於和其他同學以及老師討論
在BLOG的貼文上,又沒勤找資料
就得不到什麼感觸寫出文章來
全部包含這篇文章,全部也才貼出五篇 數量真的還滿少的
上課採討論方式
可以增加很多師生互動
觀念比較不會被全部被牽的走
如果有認真思考一下 就會比較有自己想法
所以大概只打給自己65分
Last week上課重點
JPEG隱藏方式:
Zizag編碼後,藏在
1.非0部份
2.非0和1(用來改善:因為0.1為pair,以LSB方式嵌入的話,可能會導致1變成0而錯誤)
0越多=>檔案壓縮range大
=>最後檔案小
=>可藏的位置小
J-stego:
因為DCT步驟有需要四捨五入,J-stego用佌四捨五入當作藏匿的手段
意思是:選擇藏匿的點是base on四捨五入
EX.3.34先四捨五入成3 若LSB嵌入0 則為2 實際誤差值為1.34
若是J-stego則選擇變成4 同樣是嵌入0 實際誤差為0.56 誤差值較小
entropy=>用來測量亂不亂
為何需要無失真壓縮:
因為解壓縮後=>無失真
JPEG有無失真JPEG壓縮=>再存四捨五入差值的table
以上給沒聽到課的同學參考....
Zizag編碼後,藏在
1.非0部份
2.非0和1(用來改善:因為0.1為pair,以LSB方式嵌入的話,可能會導致1變成0而錯誤)
0越多=>檔案壓縮range大
=>最後檔案小
=>可藏的位置小
J-stego:
因為DCT步驟有需要四捨五入,J-stego用佌四捨五入當作藏匿的手段
意思是:選擇藏匿的點是base on四捨五入
EX.3.34先四捨五入成3 若LSB嵌入0 則為2 實際誤差值為1.34
若是J-stego則選擇變成4 同樣是嵌入0 實際誤差為0.56 誤差值較小
entropy=>用來測量亂不亂
為何需要無失真壓縮:
因為解壓縮後=>無失真
JPEG有無失真JPEG壓縮=>再存四捨五入差值的table
以上給沒聽到課的同學參考....
[Ending]課程回顧 - 自評
我覺得到目前為止的上課有60%聽的懂
不過聽懂其實不會太難
因為上課老師都用很白話的舉例方式來講解
就像在聽故事一樣的來理解一件事情
至於那40%不懂我想就是課後自己的參與度不夠吧~
因為我並沒有每次回去都有再把上課的東西再滾過一遍來完全變成自己的
所以有時候上課都憑著上次的記憶來繼續 這是比較可惜的地方
沒複習很大的缺點就是一旦缺課就完蛋了
會一整個不知道在幹麻
所以這學期我給自己60分吧
不過聽懂其實不會太難
因為上課老師都用很白話的舉例方式來講解
就像在聽故事一樣的來理解一件事情
至於那40%不懂我想就是課後自己的參與度不夠吧~
因為我並沒有每次回去都有再把上課的東西再滾過一遍來完全變成自己的
所以有時候上課都憑著上次的記憶來繼續 這是比較可惜的地方
沒複習很大的缺點就是一旦缺課就完蛋了
會一整個不知道在幹麻
所以這學期我給自己60分吧
課程回顧與自評
課程要結束了!
這學期學到不少東西
1.S-Tool隱藏方式
2.隱藏資料在調色盤影像的index中
3.EZ-Stego的影藏方式
4.Jiri Fridrich的隱藏方法
5.JPEG的簡單了解
6.好的PowerPoint該具備的項目
我覺得讀那篇Paper學到很多
早點發應該可以學到更多JPEG的東西
因為Paper中不但提到新的方法
也對過去的方法提出介紹
不懂得地方自己上Google找
再加上PowerPoint的製作
所以印象較深刻!
唯一的小缺點是我常睡過頭
遲到或沒來上課...
其實Blog不一定只看發表的篇數
還有針對別人的文章法表意見
有發表意見表示有看過
也可以在Blog上進行討論
最後給自己77分!
這學期學到不少東西
1.S-Tool隱藏方式
2.隱藏資料在調色盤影像的index中
3.EZ-Stego的影藏方式
4.Jiri Fridrich的隱藏方法
5.JPEG的簡單了解
6.好的PowerPoint該具備的項目
我覺得讀那篇Paper學到很多
早點發應該可以學到更多JPEG的東西
因為Paper中不但提到新的方法
也對過去的方法提出介紹
不懂得地方自己上Google找
再加上PowerPoint的製作
所以印象較深刻!
唯一的小缺點是我常睡過頭
遲到或沒來上課...
其實Blog不一定只看發表的篇數
還有針對別人的文章法表意見
有發表意見表示有看過
也可以在Blog上進行討論
最後給自己77分!
[Ending]課程回顧 - 自評
課程回顧與心得評分
其實這個學期我最大的問題是天天都睡過頭吧
幾乎每天都莫名其妙很晚睡,然後早上四個鬧鐘也叫不醒
常常會遲到甚至是一口氣睡到下午所以曠課
對於課程內容,我雖然常常沒到啦....
雖然這麼講有點奇怪,但是我認為老師教的東西我應該都會吧
從調色盤影像的隱藏法到JPEG編碼過程與隱藏法
不過沒寫blog與大家討論也是我的錯
(其實是因為老師設定給大家發文權限那次我沒到
所以後來沒辦法發我也就沒去計較了)
簡報那次我也沒簡報,投影片後來做了七八成吧,但是也不好意思交了
或許也因為我對資訊隱藏也不是特別有興趣或什麼的吧
評分的話
雖然我這學期上課態度很差勁吧
不過我本著我對課程內容的瞭解
就照黃老師說的....64分好了
其實這個學期我最大的問題是天天都睡過頭吧
幾乎每天都莫名其妙很晚睡,然後早上四個鬧鐘也叫不醒
常常會遲到甚至是一口氣睡到下午所以曠課
對於課程內容,我雖然常常沒到啦....
雖然這麼講有點奇怪,但是我認為老師教的東西我應該都會吧
從調色盤影像的隱藏法到JPEG編碼過程與隱藏法
不過沒寫blog與大家討論也是我的錯
(其實是因為老師設定給大家發文權限那次我沒到
所以後來沒辦法發我也就沒去計較了)
簡報那次我也沒簡報,投影片後來做了七八成吧,但是也不好意思交了
或許也因為我對資訊隱藏也不是特別有興趣或什麼的吧
評分的話
雖然我這學期上課態度很差勁吧
不過我本著我對課程內容的瞭解
就照黃老師說的....64分好了
[Ending]課程回顧 - 自評
不知不覺間又到學期末了
當初會選這門課主要是想會對專研方面有所助益
事實也證明的確有幫助,雖然不是直接的助益
這學期學到的東西主要有兩種
1.bmp的隱藏技術:
其中學到的有基本的LSB、EZ-stego以及後來老師發那篇new method
關於LSB部分是上課前就有聽過,不過實作內容就不太了解
所以當一開始老師讓我們用stool時,我根本搞不懂這程式是做什麼用的
不過在老師仔細的講解下,這是要做什麼,以及要怎麼做就變的很清楚
而老師後來發那篇paper中則提到EZ-stego的作法及作者所提出更好的new method
EZ-stego也只是基於LSB的改良版,所以一但弄懂LSB後,要了解EZ-stego的作法並不困難
至於new method方面則又是強化加強版,它改變了色彩選擇方式,使得修改後的變異大為降低
2.jpeg的隱藏技術:
關於這部份隱藏技術的作法我是專研中就有讀到相關的東西,所以實際上並不算太陌生
而之中所使用到的轉換技術主要有三種,不過這部份上次網誌中就有提到過了
而上次黃世育老師代課時有提到DCT的部份,雖然他說自己也不完全知道這是怎樣的東西
不過講解的內容還是能讓大家有個基本的了解
總觀下來,這學期雖然充滿了摸魚的氣息
其中甚至有幾天跟小安一樣躲在家裡看MLB
不過關於上課所學到的內容,我有自信全都有弄懂
所以最後我給自己的期末評分為:65分
當初會選這門課主要是想會對專研方面有所助益
事實也證明的確有幫助,雖然不是直接的助益
這學期學到的東西主要有兩種
1.bmp的隱藏技術:
其中學到的有基本的LSB、EZ-stego以及後來老師發那篇new method
關於LSB部分是上課前就有聽過,不過實作內容就不太了解
所以當一開始老師讓我們用stool時,我根本搞不懂這程式是做什麼用的
不過在老師仔細的講解下,這是要做什麼,以及要怎麼做就變的很清楚
而老師後來發那篇paper中則提到EZ-stego的作法及作者所提出更好的new method
EZ-stego也只是基於LSB的改良版,所以一但弄懂LSB後,要了解EZ-stego的作法並不困難
至於new method方面則又是強化加強版,它改變了色彩選擇方式,使得修改後的變異大為降低
2.jpeg的隱藏技術:
關於這部份隱藏技術的作法我是專研中就有讀到相關的東西,所以實際上並不算太陌生
而之中所使用到的轉換技術主要有三種,不過這部份上次網誌中就有提到過了
而上次黃世育老師代課時有提到DCT的部份,雖然他說自己也不完全知道這是怎樣的東西
不過講解的內容還是能讓大家有個基本的了解
總觀下來,這學期雖然充滿了摸魚的氣息
其中甚至有幾天跟小安一樣躲在家裡看MLB
不過關於上課所學到的內容,我有自信全都有弄懂
所以最後我給自己的期末評分為:65分
課程回顧&自我評分
本學期因為想要延續對多媒體領域的認知
所以選了這門資訊隱藏的課程
果然也獲得了一些不錯的經驗
雖然老師並沒有強迫與要求我們寫程式
但對我而言每一次寫程式的經驗都是一種自我能力的
充實與培養,而且對我而言如果一個學期不寫點程式玩玩
總感覺會怪怪的.....寫了之後果然是非常舒暢!
去思考如何把資料隱藏還蠻好玩的
此外對於幾種基本圖片的檔案格式,除了以前常用的bmp格式以外
對gif以及jpeg也有了初步的了解,可惜的是接觸jpeg的時間太短
不然我感覺這也會是一塊很有挑戰性的領域,大概可以單獨分開一學期的課了吧!
在閱讀paper及製作投影片的練習時,算是我這學期最大的收穫吧!
因為我深深的感覺到了自己本身的缺陷和可以修改的進步空間
對於整理及統整這方面的功夫我做的實在不太好,這對我而言是個很好的警惕
因為未來如果我繼續升學,如果不改正上述的缺點
到時我勢必會遇到很大的挫折與麻煩
至於課堂討論方面
感謝小華與可欣常常願意跟我分享她們的想法
有時會讓我有茅塞頓開的感覺!
若要說我對自己的感到最不滿的地方
就是我的出席率吧
升上大四的我真的有點混
抱著等畢業的心態變的不太積極
常常會給自己太多的理由睡過頭
其實根本就沒啥理由打混就是打混
因此總結以上幾點我覺得我可以給自己打70分
所以選了這門資訊隱藏的課程
果然也獲得了一些不錯的經驗
雖然老師並沒有強迫與要求我們寫程式
但對我而言每一次寫程式的經驗都是一種自我能力的
充實與培養,而且對我而言如果一個學期不寫點程式玩玩
總感覺會怪怪的.....寫了之後果然是非常舒暢!
去思考如何把資料隱藏還蠻好玩的
此外對於幾種基本圖片的檔案格式,除了以前常用的bmp格式以外
對gif以及jpeg也有了初步的了解,可惜的是接觸jpeg的時間太短
不然我感覺這也會是一塊很有挑戰性的領域,大概可以單獨分開一學期的課了吧!
在閱讀paper及製作投影片的練習時,算是我這學期最大的收穫吧!
因為我深深的感覺到了自己本身的缺陷和可以修改的進步空間
對於整理及統整這方面的功夫我做的實在不太好,這對我而言是個很好的警惕
因為未來如果我繼續升學,如果不改正上述的缺點
到時我勢必會遇到很大的挫折與麻煩
至於課堂討論方面
感謝小華與可欣常常願意跟我分享她們的想法
有時會讓我有茅塞頓開的感覺!
若要說我對自己的感到最不滿的地方
就是我的出席率吧
升上大四的我真的有點混
抱著等畢業的心態變的不太積極
常常會給自己太多的理由睡過頭
其實根本就沒啥理由打混就是打混
因此總結以上幾點我覺得我可以給自己打70分
[final]課程回顧+分數
又到了期末算總帳的時候了
我覺得大家都po給自己的分數這招真是個大絕耶
本來想說隨隨便便給打個八十左右就好了
反正姊姊不擅長打分數這檔子事
付出多少就得到多少
對得起自己就好了
那個分數無異議啦
沒想到大家都給自己偏低的分數耶
天ㄚ
大家都好認真的對自己打分數喔
原本我覺得應該會很高分的政瑋也給自己70耶
嘖!!我覺得他應該要比我高個5~10分的說
這樣我不就剛好及格邊緣了~囧
而且大家都有列自己的缺點耶
那我也仔細檢討一下好了
-----我是檢討分隔線-----
好吧...我必須承認...
我每個禮拜都有遲到...
如果以這個來看我早就負分了啦XDD
BLOG也都是老師盯了才寫
雖然每次寫的都很長一篇...
但是那個篇數太少了...
而且都喇賽文衝字數的啦...
根據一連串詭異的公式推出來之後
我獲得的分數是46.25
-----我是檢討分隔線-----
我才不想承認這個不及格的分數咧(/‵′)/~ ╧╧
管他的
哪有人算那麼細的
我70好了啦 跟小狐貍學長ㄧ樣XDD
好了
喇賽的給自己打分數到此結束
接下來是認真的課程回顧+心得!!
----我是心得分隔線----
基本上
"資訊隱藏"這門課呢
跟我之後的研究有非常大的相關性
偶而這邊的東西會跟meeting搞混掉
我沒辦法像其他同學一樣
說出一個在這門課裡明確學習到的東西
(而且且那些東西在過去的網誌裡也都有講到了...重講一遍也很怪....)
但至少
有這門課
讓我對於未來的研究方向
不再只是個看不到卻沒有實體感
像是空氣一樣模糊的東西
經過這門課以後
對於未來的領域
應該可以圈出個範圍了
以上
就是我對這門課的感想...
我覺得大家都po給自己的分數這招真是個大絕耶
本來想說隨隨便便給打個八十左右就好了
反正姊姊不擅長打分數這檔子事
付出多少就得到多少
對得起自己就好了
那個分數無異議啦
沒想到大家都給自己偏低的分數耶
天ㄚ
大家都好認真的對自己打分數喔
原本我覺得應該會很高分的政瑋也給自己70耶
嘖!!我覺得他應該要比我高個5~10分的說
這樣我不就剛好及格邊緣了~囧
而且大家都有列自己的缺點耶
那我也仔細檢討一下好了
-----我是檢討分隔線-----
好吧...我必須承認...
我每個禮拜都有遲到...
如果以這個來看我早就負分了啦XDD
BLOG也都是老師盯了才寫
雖然每次寫的都很長一篇...
但是那個篇數太少了...
而且都喇賽文衝字數的啦...
根據一連串詭異的公式推出來之後
我獲得的分數是46.25
-----我是檢討分隔線-----
我才不想承認這個不及格的分數咧(/‵′)/~ ╧╧
管他的
哪有人算那麼細的
我70好了啦 跟小狐貍學長ㄧ樣XDD
好了
喇賽的給自己打分數到此結束
接下來是認真的課程回顧+心得!!
----我是心得分隔線----
基本上
"資訊隱藏"這門課呢
跟我之後的研究有非常大的相關性
偶而這邊的東西會跟meeting搞混掉
我沒辦法像其他同學一樣
說出一個在這門課裡明確學習到的東西
(而且且那些東西在過去的網誌裡也都有講到了...重講一遍也很怪....)
但至少
有這門課
讓我對於未來的研究方向
不再只是個看不到卻沒有實體感
像是空氣一樣模糊的東西
經過這門課以後
對於未來的領域
應該可以圈出個範圍了
以上
就是我對這門課的感想...
Week16
1. 針對每一個經 DCT 轉換後所得到的 8*8 係數矩陣, 都要使用一個同樣是 8*8 大小的量化矩陣做量化壓縮程序。為什麼量化矩陣中, 不同位置的值大小不同, 代表的涵義為何?
我覺得量化矩陣的用處是將原本的矩陣能量化分成兩個部份,一個是低頻,一個是高頻,因為量化後的矩陣有比較大的差別,我們人類對於高頻率的事物比較不敏感,所以在壓縮方面可以減少高頻率的資料,讓壓縮更為有效率
2. 量化後的係數矩陣中, 存在許多個 0, 代表的涵義為何?
0代表的是高頻,在資料壓縮方面可以減少資料的壓縮,提高壓縮的效率
3. 用 Zigzag 的方式, 將二維矩陣轉換為一維矩陣的目的為何? 優點為何?
Zigzag 的方式是將量化後的矩陣轉換為一維的陣列,是因為後面高頻大部份的數字都是0,我們可以將後面的0都去掉改為EOB代替
優點:可以減少資料的讀取的時間,減少檔案的大小
4. 為什麼 JPEG 壓縮的最後一個步驟必須使用無失真的壓縮技術?
我絕得它只是想減少更多不必要的資料,例如後面高頻的0,而且之前的處理已經壓縮過一次了,那如果用有失真的壓縮再壓縮一次,應該會減少圖片的品質吧
5. 熵編碼(entropy coding)的熵所代表的意義為何?
在網路上看過別人的解釋,有但沒有懂@@”
同學們了解了整個 JPEG 壓縮過程後, 就可以自行思索如果想嵌入機密訊息到 JPEG 影像中, 可以放到哪個位置之中。
思索一下隱藏的資訊可以放到哪裡,我絕得是放在Z字型的一維陣列,因為其他的步驟感覺是制式的,DCT的轉換是經過一個座標轉換(套公式),量化也是經過一個量化矩陣,而且在轉換過程中數字的變化還蠻大的,最後的那個無失真壓縮只是把多餘的0去掉,應該可以在上面動個手腳,只是不知道怎麼藏而已
以上是以我所知道的來回答,有錯的請指教
我覺得量化矩陣的用處是將原本的矩陣能量化分成兩個部份,一個是低頻,一個是高頻,因為量化後的矩陣有比較大的差別,我們人類對於高頻率的事物比較不敏感,所以在壓縮方面可以減少高頻率的資料,讓壓縮更為有效率
2. 量化後的係數矩陣中, 存在許多個 0, 代表的涵義為何?
0代表的是高頻,在資料壓縮方面可以減少資料的壓縮,提高壓縮的效率
3. 用 Zigzag 的方式, 將二維矩陣轉換為一維矩陣的目的為何? 優點為何?
Zigzag 的方式是將量化後的矩陣轉換為一維的陣列,是因為後面高頻大部份的數字都是0,我們可以將後面的0都去掉改為EOB代替
優點:可以減少資料的讀取的時間,減少檔案的大小
4. 為什麼 JPEG 壓縮的最後一個步驟必須使用無失真的壓縮技術?
我絕得它只是想減少更多不必要的資料,例如後面高頻的0,而且之前的處理已經壓縮過一次了,那如果用有失真的壓縮再壓縮一次,應該會減少圖片的品質吧
5. 熵編碼(entropy coding)的熵所代表的意義為何?
在網路上看過別人的解釋,有但沒有懂@@”
同學們了解了整個 JPEG 壓縮過程後, 就可以自行思索如果想嵌入機密訊息到 JPEG 影像中, 可以放到哪個位置之中。
思索一下隱藏的資訊可以放到哪裡,我絕得是放在Z字型的一維陣列,因為其他的步驟感覺是制式的,DCT的轉換是經過一個座標轉換(套公式),量化也是經過一個量化矩陣,而且在轉換過程中數字的變化還蠻大的,最後的那個無失真壓縮只是把多餘的0去掉,應該可以在上面動個手腳,只是不知道怎麼藏而已
以上是以我所知道的來回答,有錯的請指教
2007年6月20日 星期三
課程回顧
課程回顧:
認識S-Tool,並實際去操作此軟體
程式:
1.將圖片最後一個位元抽取出來,拼湊成一張黑白影像!!
2.算出一張黑白影像,兩兩相鄰的值為相同的機率之期望值為多少!!並判斷是否屬於
random pattern。
Index embedding
程式:
1.撰寫一個模擬將機密訊息嵌入到調色盤類型影像的索引值中,藉以分析原始掩護
影像(cover-images)與偽裝影像(steg0-images)之間的變化。
Jessica Fridrich Method
讀這篇論文,並提出問題,並將論文試著分工合作,做成投影片!!並試著上台ㄑ報告!
再次修改投影片把不好的地方修改好!!
JPEG Compression
讀JPEG的介紹(維基百科的文章)!!認識JPEG的原理!!並提出問題!!!
心的:
資訊隱藏這們課一開始對於我是個很新的課程!!雖然之前有接觸一點點!!但是對於資訊隱
藏還不太了解!!加上因為是上修!!所以很害怕跟不上學長姐!!!
經過將近半年的接觸!!!不敢說對資訊隱藏很熟!!但是對於一開始的懵懵懂懂!!!學習到了
GIF的隱藏法,如何先將一個JPEG圖片存成GIF再將他存成BMP!!把調色盤給話出來!!再將資訊藏入Index中,並去探討此隱藏有何種缺點如何去改進,學習到利用相近的顏色來隱藏資訊,使圖片失真降低,改善之前隱藏的缺點!!
練習讀論文,因為以前沒有讀過論文所以這篇論文花了我不少時間!!之後看懂文章才發現
現文中有很多方法都是我們有練習過的程式~~更加深刻!!!並且也學習到如何ㄑ整理論文,做成
PowerPoint,學習到上台報告的技巧!!學習其他人的優缺點!!並再次改進自己的缺點!!!
這堂課中~~我們不只單單只學習到有關資訊隱藏的方法!!學習到如何找出問題~~~解決別人的問題!!!提出問題!!!並且互相討論!!!
對於這堂課~~我盡力ㄑ做到最好了!!!所以我給自己70分!!!!
認識S-Tool,並實際去操作此軟體
程式:
1.將圖片最後一個位元抽取出來,拼湊成一張黑白影像!!
2.算出一張黑白影像,兩兩相鄰的值為相同的機率之期望值為多少!!並判斷是否屬於
random pattern。
Index embedding
程式:
1.撰寫一個模擬將機密訊息嵌入到調色盤類型影像的索引值中,藉以分析原始掩護
影像(cover-images)與偽裝影像(steg0-images)之間的變化。
Jessica Fridrich Method
讀這篇論文,並提出問題,並將論文試著分工合作,做成投影片!!並試著上台ㄑ報告!
再次修改投影片把不好的地方修改好!!
JPEG Compression
讀JPEG的介紹(維基百科的文章)!!認識JPEG的原理!!並提出問題!!!
心的:
資訊隱藏這們課一開始對於我是個很新的課程!!雖然之前有接觸一點點!!但是對於資訊隱
藏還不太了解!!加上因為是上修!!所以很害怕跟不上學長姐!!!
經過將近半年的接觸!!!不敢說對資訊隱藏很熟!!但是對於一開始的懵懵懂懂!!!學習到了
GIF的隱藏法,如何先將一個JPEG圖片存成GIF再將他存成BMP!!把調色盤給話出來!!再將資訊藏入Index中,並去探討此隱藏有何種缺點如何去改進,學習到利用相近的顏色來隱藏資訊,使圖片失真降低,改善之前隱藏的缺點!!
練習讀論文,因為以前沒有讀過論文所以這篇論文花了我不少時間!!之後看懂文章才發現
現文中有很多方法都是我們有練習過的程式~~更加深刻!!!並且也學習到如何ㄑ整理論文,做成
PowerPoint,學習到上台報告的技巧!!學習其他人的優缺點!!並再次改進自己的缺點!!!
這堂課中~~我們不只單單只學習到有關資訊隱藏的方法!!學習到如何找出問題~~~解決別人的問題!!!提出問題!!!並且互相討論!!!
對於這堂課~~我盡力ㄑ做到最好了!!!所以我給自己70分!!!!
課程回顧與心得
[課程回顧]
還記得第一堂課,老師先從資訊隱藏的歷史說起,
逐漸把我們從理論帶入實作。
程式方面,
一開始是先從S-Tools玩起。
在研究S-Tools的同時,
思考破解的方法以及,過去曾經用來藏資料的手法。
看了一些跟Bitmap,GIF藏資料有關的程式
(也動手寫了一點相關的程式)
大概的了解了.bmp跟.Gif的藏資料方式
後來研究了一篇跟parity有關的paper
練習上台報告還有做power point
因為那份power point我是盡了全力去做的,
所以當老師希望我們試著修改時,
我真的想不出要怎麼改,目前也還是想不出。
(應該是功力不足的關係吧 囧)
尾聲就是準備開始進入JPEG的世界
[心得]
資訊隱藏對我來說,是一門上修的課,
有一些比較專業術語的部份,反應上就會比較慢,
(有的是沒聽過,有的是聽過但不知道在做什麼)
還得讓老師多次解釋,感到很不好意思,哈。
(那個覺得只有自己跟不上的問卷就是我寫的...(汗))
沒有跟著進度把所有程式(作業)都試著寫出來是我心中小小的遺憾。
自評的部份,如果我說我想給自己70不知道會不會太高(汗)
捫心自問,總覺得自己少了那麼一點努力,足以扣掉三成的分數。
還記得第一堂課,老師先從資訊隱藏的歷史說起,
逐漸把我們從理論帶入實作。
程式方面,
一開始是先從S-Tools玩起。
在研究S-Tools的同時,
思考破解的方法以及,過去曾經用來藏資料的手法。
看了一些跟Bitmap,GIF藏資料有關的程式
(也動手寫了一點相關的程式)
大概的了解了.bmp跟.Gif的藏資料方式
後來研究了一篇跟parity有關的paper
練習上台報告還有做power point
因為那份power point我是盡了全力去做的,
所以當老師希望我們試著修改時,
我真的想不出要怎麼改,目前也還是想不出。
(應該是功力不足的關係吧 囧)
尾聲就是準備開始進入JPEG的世界
[心得]
資訊隱藏對我來說,是一門上修的課,
有一些比較專業術語的部份,反應上就會比較慢,
(有的是沒聽過,有的是聽過但不知道在做什麼)
還得讓老師多次解釋,感到很不好意思,哈。
(那個覺得只有自己跟不上的問卷就是我寫的...(汗))
沒有跟著進度把所有程式(作業)都試著寫出來是我心中小小的遺憾。
自評的部份,如果我說我想給自己70不知道會不會太高(汗)
捫心自問,總覺得自己少了那麼一點努力,足以扣掉三成的分數。
week16 - 給自己打分數
我給自己打70分。
課程感想:
這堂課一開始時我覺得自己有點跟不上
完全是一個路人跑進來的感覺
腦中缺乏這門課的相關基礎知識
聽了老師的解說後也欠缺自行複習
感想也不太會寫
嗯......就是在混||b
開始可以寫程式的時候才開始進入狀況
很認真寫程式
而這裡的印象也相對地深刻
所以這七十分是為我之後的努力所打的
課程感想:
這堂課一開始時我覺得自己有點跟不上
完全是一個路人跑進來的感覺
腦中缺乏這門課的相關基礎知識
聽了老師的解說後也欠缺自行複習
感想也不太會寫
嗯......就是在混||b
開始可以寫程式的時候才開始進入狀況
很認真寫程式
而這裡的印象也相對地深刻
所以這七十分是為我之後的努力所打的
心得與自我評分
上了一學期的資訊隱藏,其實學到的東西不只是如何去隱藏資訊,對於圖檔上也有初步的了解,
老師利用Blog的方式,開放讓同學在線上可以發表自己的想法,
對於沒有去上到課的同學,老師也有貼心的把上課大綱放在Blog上,可以讓有興趣的同學跟上進度
老師比較注重"互動"
我覺得如果可以分為小組的方式,打散各年層的,以競賽團體的方式作為加分的依據,並不代表一人得道雞犬升天,而是可以促進討論以及讓膽大感發表的人代替比較害羞的同學表達意見,懂的比較多的人也可以為同組的同學做講解,不僅可以讓他們追上也可以促進友誼
這學期有缺大概三到四次課,大部分都是自己的問題,除了早上才入眠加上抽兵種,是可以多加改進的地方
但是每次都是和政偉同學為最早到的幾個人,沒有途中插入的現象
對於上課討論學習到的議題,回去也會立刻迫不及待的寫程式做實驗
對於自己突然的想法也會做實作
雖然自己非優秀的學生,但也不至於混水摸魚,給自己的分數是70
老師利用Blog的方式,開放讓同學在線上可以發表自己的想法,
對於沒有去上到課的同學,老師也有貼心的把上課大綱放在Blog上,可以讓有興趣的同學跟上進度
老師比較注重"互動"
我覺得如果可以分為小組的方式,打散各年層的,以競賽團體的方式作為加分的依據,並不代表一人得道雞犬升天,而是可以促進討論以及讓膽大感發表的人代替比較害羞的同學表達意見,懂的比較多的人也可以為同組的同學做講解,不僅可以讓他們追上也可以促進友誼
這學期有缺大概三到四次課,大部分都是自己的問題,除了早上才入眠加上抽兵種,是可以多加改進的地方
但是每次都是和政偉同學為最早到的幾個人,沒有途中插入的現象
對於上課討論學習到的議題,回去也會立刻迫不及待的寫程式做實驗
對於自己突然的想法也會做實作
雖然自己非優秀的學生,但也不至於混水摸魚,給自己的分數是70
期末算帳
資訊隱藏上一學期了,終於到了期未算帳的時刻了~~
總之…先來個回想…
當初選資隱時,對這門課的內容並沒有想太多
只是單純以為以加密或以掩護隱藏的方式將資料藏起來,不讓人知道
不過也是這樣才知道這和密碼學是有很大的落差的
畢竟要將資料隱藏於媒介中而又不能被任何人起疑心
以及在相同的媒介中如何放入最大的資料量而又不能被破解
這是有相當難度的
一開始以BMP圖檔來做簡單實驗,以這個做為入門其實不錯
不只可以對資隱有一些了解,對於接下來的各種隱藏方法也能快速理解
自已有小試一下簡單的隱藏方法,結果之拙劣更顯示出好演算法的必要性
在有快速傳送的前提下,檔案當然是愈小愈高興
而圖檔的 size 小,而且又廣泛
尤其是 jpeg 的大壓縮技術,真是讓人激起征服的慾望
把資訊放入圖檔似乎有著挑戰而又安全便利的優點
但其實資隱的範圍應該可以更廣,不應該只提到圖檔的隱藏
數位的媒介是很多的,舉凡音樂檔、視訊檔甚至文件檔也應該能發揮
一學期能夠學到的真的太少了…
最後…又到了自我評評評的時間
我真的覺得,每次給自已打努力分數,我都想給自已 100 分…
所以,我使用扣分制!
以每星期 po blog 的作業,嗯…我不努力
因為在網路上 po 文給別人看,如果是沒營養的文,我自已都受不了
所以我不勉強自已的結果,就扣 20 分吧
上課無故缺席部分…只能怪職棒太巧都撞在星期四
因上述藉口,扣自已 12 分
我給自已打 68 分
總之…先來個回想…
當初選資隱時,對這門課的內容並沒有想太多
只是單純以為以加密或以掩護隱藏的方式將資料藏起來,不讓人知道
不過也是這樣才知道這和密碼學是有很大的落差的
畢竟要將資料隱藏於媒介中而又不能被任何人起疑心
以及在相同的媒介中如何放入最大的資料量而又不能被破解
這是有相當難度的
一開始以BMP圖檔來做簡單實驗,以這個做為入門其實不錯
不只可以對資隱有一些了解,對於接下來的各種隱藏方法也能快速理解
自已有小試一下簡單的隱藏方法,結果之拙劣更顯示出好演算法的必要性
在有快速傳送的前提下,檔案當然是愈小愈高興
而圖檔的 size 小,而且又廣泛
尤其是 jpeg 的大壓縮技術,真是讓人激起征服的慾望
把資訊放入圖檔似乎有著挑戰而又安全便利的優點
但其實資隱的範圍應該可以更廣,不應該只提到圖檔的隱藏
數位的媒介是很多的,舉凡音樂檔、視訊檔甚至文件檔也應該能發揮
一學期能夠學到的真的太少了…
最後…又到了自我評評評的時間
我真的覺得,每次給自已打努力分數,我都想給自已 100 分…
所以,我使用扣分制!
以每星期 po blog 的作業,嗯…我不努力
因為在網路上 po 文給別人看,如果是沒營養的文,我自已都受不了
所以我不勉強自已的結果,就扣 20 分吧
上課無故缺席部分…只能怪職棒太巧都撞在星期四
因上述藉口,扣自已 12 分
我給自已打 68 分
Week 16: JEPG compression (2)
1. 針對每一個經 DCT 轉換後所得到的 8*8 係數矩陣, 都要使用一個同樣是 8*8 大小的量化矩陣做量化壓縮程序。為什麼量化矩陣中, 不同位置的值大小不同, 代表的涵義為何?
因為各式和前面的差距,即變動的幅度
2. 量化後的係數矩陣中, 存在許多個 0, 代表的涵義為何?
彼此間的差異不大,沒什麼變化
3. 用 Zigzag 的方式, 將二維矩陣轉換為一維矩陣的目的為何? 優點為何?
目的在於可以方便壓縮,優點是:對於後面連續的0可以省略
4. 為什麼 JPEG 壓縮的最後一個步驟必須使用無失真的壓縮技術?
還不甚清楚....
5. 熵編碼(entropy coding)的熵所代表的意義為何?
以下是搜尋到的相關文章,提出跟同學分享
http://episte.math.ntu.edu.tw/articles/mm/mm_13_3_01/index.html
因為各式和前面的差距,即變動的幅度
2. 量化後的係數矩陣中, 存在許多個 0, 代表的涵義為何?
彼此間的差異不大,沒什麼變化
3. 用 Zigzag 的方式, 將二維矩陣轉換為一維矩陣的目的為何? 優點為何?
目的在於可以方便壓縮,優點是:對於後面連續的0可以省略
4. 為什麼 JPEG 壓縮的最後一個步驟必須使用無失真的壓縮技術?
還不甚清楚....
5. 熵編碼(entropy coding)的熵所代表的意義為何?
以下是搜尋到的相關文章,提出跟同學分享
http://episte.math.ntu.edu.tw/articles/mm/mm_13_3_01/index.html
Week 15: JEPG compression (1)
討論的內容包含:
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
我覺得應該是對於一種色彩的表示方式和計算方法可以視為一個空間,像是線性代數常用的歐式空間等,
色彩的表示方式很多,所以有不同的表示方式,用來加強某些部分的表現程度,所以有不同的色彩空間,
轉換的目的再於讓以某種的表示方式改成另一種,方便日後計算跟表示
2. 什麼是量化? 好處是什麼?
字面上意義應該是說"數量化",很多科學的東西都會提到"量化",像是分等級,用來比較之類的,若是沒有數量化,則很多事情就會變的比較不精確,像是比身高體重等!量化的好處就在於可以讓要描述的東西容易比較,且容易表達
3. 什麼是轉換? 為什麼要做 DCT 轉換?
從一個性質變成另一個性質,為何要做DCT轉換,DCT轉換比較符合自然現象的表現
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
低頻:單位時間震動次數較少的波形
高頻:單位時間震動次數較多的波形
代表亮度的頻率
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
我覺得應該是對於一種色彩的表示方式和計算方法可以視為一個空間,像是線性代數常用的歐式空間等,
色彩的表示方式很多,所以有不同的表示方式,用來加強某些部分的表現程度,所以有不同的色彩空間,
轉換的目的再於讓以某種的表示方式改成另一種,方便日後計算跟表示
2. 什麼是量化? 好處是什麼?
字面上意義應該是說"數量化",很多科學的東西都會提到"量化",像是分等級,用來比較之類的,若是沒有數量化,則很多事情就會變的比較不精確,像是比身高體重等!量化的好處就在於可以讓要描述的東西容易比較,且容易表達
3. 什麼是轉換? 為什麼要做 DCT 轉換?
從一個性質變成另一個性質,為何要做DCT轉換,DCT轉換比較符合自然現象的表現
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
低頻:單位時間震動次數較少的波形
高頻:單位時間震動次數較多的波形
代表亮度的頻率
2007年6月19日 星期二
week 16 : 給自己打分數
上了一學期的資訊隱藏
從第一堂課開始介紹資訊隱藏(藏匿學)與密碼學
了解藏匿學和密碼學兩者的相似與相異之處,兩者的訴求不同。
剛好我這學期 上數位簽章牽涉到很多加解密的方法,
而資訊隱藏這門課剛好互補,是屬於藏匿學的部份
這堂課的要求是多參予討論,上完課後到BLOG留個紀錄
我喜歡小班制這樣的上課模式,上課可以問問題。
我認為台灣的學生,對於問問題實在是感覺到非常恐懼
有害羞的,也有不懂裝懂的,大家都還不習慣這種上課方式
因為從高中開始就是這樣填壓式的學習,
高中老師說什麼就是什麼,問問題,老師也不見得回答你
他反而要求你要自己回家多看書。
我認為興趣很重要,我在高中的時候,對英文最有興趣
有很大的部份是因為我喜歡那個老師上課的方式,
他跟我說: 人的心本來就是偏的,你若偏心英文,英文就會偏心你。
我聽說一年級的歷史課,有位老師鼓勵學生多問問題,多發表意見
那位歷史老師說,只要舉手亂發表建議,回答問題不論對錯,
都可以拿獎金壹百元 ,課後留下一些時間讓同學上台,隨便講任何事情,
說笑話也好,談自己的生活也好,只要上台發表就有獎金
聽說他們上課的舉手風氣很熱絡。
我聽到學弟在述說這件事情的時候,覺得這位教授很有遠見,
因為他抓到台灣教育最大的核心問題,學生不懂不問,又愛裝懂。
雖然上一門的課,他所花的cost比較高一點,
藉由這種手段,也許達到他要的效果與目的。
而資訊隱藏這門課,希望用討論的方式來上課,我覺得出發點很好,
但是我認為討論的還是太少,應該要去想一個好的方式讓學生參予更多,
另外一方面是學生自己太害羞也是個問題。
我覺得資工系要好,應該要先從讓學生舉手,主動式學習開始,
從一年級就要開始。
被動式學習是教授給什麼就接受什麼,全面吸收,這樣比較不好。
我一年級進資工,覺得超沒有興趣的,教授一開口,滿嘴英文
對於電腦白癡的我,真的是鴨子聽雷
我覺得"沒有興趣"和"不曉得資工在幹麻" 是一年級最大的問題
所以我認為教授引導學生產生興趣很重要,還有鼓勵舉手這件事
對我來說啟蒙最大的是顏老師,他經常鼓勵我不要怕,盡量舉手
不管說對說錯,都加分,因為舉手就是一種勇氣
我今年有修軍訓課,軍訓老師也希望有互動,但是還是沒有互動
為什麼?
我覺得台灣的學生太害羞,當你給他們機會舉手發問的時候,
大多都不敢舉手,還有在意別人的眼光,怕別人覺得自己很笨
請給他們一些時間,讓他們能和自己心中的阻礙抗衡
大多的學生都還在猶豫要不要舉手的時候
教官已經跳開到另外一個話題了
不要期盼所有的學生都舉手,像所有的研究一樣
我們講的不是百分之百的效能,我們講究的是"提升了多少效能"
從0個人舉手,到五六個人舉手問問題,參予討論,這就是提升的部份
從LSB 到Index Embedded,講究的並不是毫無破綻的藏匿
講究的是 How much you can improve ?
這句話,算是我上課我受益良多的一句話。
回到正題,這學期學了兩種資訊隱藏的方法,接下來還要學第三種
一種是LSB 一種是Index Embedded,這兩種都是用於調色盤 based 的藏匿方式
之後還要學習 JPEG 的藏匿方法。
在藏匿學的課中,除了思考藏的方式,也去想破解的方式。
還有討論如何去判斷圖是否為一張亂亂的影像。要大家去思考。
之後看了一篇論文,這篇論文是我在大學第一篇關於多媒體領域的論文
然後教授要我們看這篇論文提出問題,
不管多簡單的問題都可以問,包括英文單字也可以問。
然後要我們做投影片報告這篇論文,然後指出作報告時的優缺點,
我喜歡這樣的上課方式,下次若有類似的課程,
我希望多發幾篇論文給學生看,做小組分工
然後上台報告的人接受底下的人問問題,是問問題、給意見而不是批判(評)
最好高年級跟低年級穿插在同一組
因為這樣學弟妹可以直接從學長姐身上學到作投影片的經驗,還有報告的經驗
這樣會更像做研究。
因為我覺得研究就是 抓住別人的缺點,掌握自己的優點
然後改善別人的缺點,增強自己的優點
我現在開始跟教授作研究了,我們報告的時候,教授和學長姐在下面問問題
我深覺一件事情: 教授也不是萬能的,他們也會問問題,他們也有問題
教授都有問題了,作為學生的,問問題的風氣和能力不應該比教授還要差
顏老師跟我說: 等你唸到博士碩士,已經不是老師交你了,而是反過來
你要去交老師,老師只給你一些方向和建議
這門課,教授在課堂上給我們看過一個影片 -- 地球是平的
那個影片的確也shock到我了,我大學所學的東西,
說實在的,在沒有複習的情況下,忘的一乾二淨,不記得學了些什麼
像影片所說的,只有不變的東西留下來-- 態度
我記得有一次上課,是要拿自己改進的投影片上台,
我想說我的投影片只有兩頁,實在是沒有什麼好改進的,
但是看到教授的投影片後,他說他改了一個禮拜,
圖都重新畫,我心中OS: 教授怎麼比學生還認真!!
這件事情給了我一個觀念,投影片要精心策劃,每一張投影片都要有功能
報告的時候要抓重點,怎麼抓重點需要學習
所以在未來研究所的課程裡,我立志論文中的圖能重畫盡量重畫
因為會比較清楚,而且可以加入動畫
以前有一個英文老師對我說: 上台就是一種表演,表演是一種藝術
而我認為,若上台報告是種表演,
在舞台上Focus住觀眾,也就是Focus住了Money
甚至讓觀眾很期待你的下一次表演。
這學期的資訊隱藏課程,上課方式我很喜歡,
我的優點是上課積極參與討論,經常私下和本泰可欣討論
出席狀況良好,沒有遲到過,BLOG 的篇數還可以
缺點是BLOG寫的不夠豐富,沒有寫程式,有一兩次缺席
對於課程內容了解與滿意,清楚課程目標
我給自己的分數是 70 分。
從第一堂課開始介紹資訊隱藏(藏匿學)與密碼學
了解藏匿學和密碼學兩者的相似與相異之處,兩者的訴求不同。
剛好我這學期 上數位簽章牽涉到很多加解密的方法,
而資訊隱藏這門課剛好互補,是屬於藏匿學的部份
這堂課的要求是多參予討論,上完課後到BLOG留個紀錄
我喜歡小班制這樣的上課模式,上課可以問問題。
我認為台灣的學生,對於問問題實在是感覺到非常恐懼
有害羞的,也有不懂裝懂的,大家都還不習慣這種上課方式
因為從高中開始就是這樣填壓式的學習,
高中老師說什麼就是什麼,問問題,老師也不見得回答你
他反而要求你要自己回家多看書。
我認為興趣很重要,我在高中的時候,對英文最有興趣
有很大的部份是因為我喜歡那個老師上課的方式,
他跟我說: 人的心本來就是偏的,你若偏心英文,英文就會偏心你。
我聽說一年級的歷史課,有位老師鼓勵學生多問問題,多發表意見
那位歷史老師說,只要舉手亂發表建議,回答問題不論對錯,
都可以拿獎金壹百元 ,課後留下一些時間讓同學上台,隨便講任何事情,
說笑話也好,談自己的生活也好,只要上台發表就有獎金
聽說他們上課的舉手風氣很熱絡。
我聽到學弟在述說這件事情的時候,覺得這位教授很有遠見,
因為他抓到台灣教育最大的核心問題,學生不懂不問,又愛裝懂。
雖然上一門的課,他所花的cost比較高一點,
藉由這種手段,也許達到他要的效果與目的。
而資訊隱藏這門課,希望用討論的方式來上課,我覺得出發點很好,
但是我認為討論的還是太少,應該要去想一個好的方式讓學生參予更多,
另外一方面是學生自己太害羞也是個問題。
我覺得資工系要好,應該要先從讓學生舉手,主動式學習開始,
從一年級就要開始。
被動式學習是教授給什麼就接受什麼,全面吸收,這樣比較不好。
我一年級進資工,覺得超沒有興趣的,教授一開口,滿嘴英文
對於電腦白癡的我,真的是鴨子聽雷
我覺得"沒有興趣"和"不曉得資工在幹麻" 是一年級最大的問題
所以我認為教授引導學生產生興趣很重要,還有鼓勵舉手這件事
對我來說啟蒙最大的是顏老師,他經常鼓勵我不要怕,盡量舉手
不管說對說錯,都加分,因為舉手就是一種勇氣
我今年有修軍訓課,軍訓老師也希望有互動,但是還是沒有互動
為什麼?
我覺得台灣的學生太害羞,當你給他們機會舉手發問的時候,
大多都不敢舉手,還有在意別人的眼光,怕別人覺得自己很笨
請給他們一些時間,讓他們能和自己心中的阻礙抗衡
大多的學生都還在猶豫要不要舉手的時候
教官已經跳開到另外一個話題了
不要期盼所有的學生都舉手,像所有的研究一樣
我們講的不是百分之百的效能,我們講究的是"提升了多少效能"
從0個人舉手,到五六個人舉手問問題,參予討論,這就是提升的部份
從LSB 到Index Embedded,講究的並不是毫無破綻的藏匿
講究的是 How much you can improve ?
這句話,算是我上課我受益良多的一句話。
回到正題,這學期學了兩種資訊隱藏的方法,接下來還要學第三種
一種是LSB 一種是Index Embedded,這兩種都是用於調色盤 based 的藏匿方式
之後還要學習 JPEG 的藏匿方法。
在藏匿學的課中,除了思考藏的方式,也去想破解的方式。
還有討論如何去判斷圖是否為一張亂亂的影像。要大家去思考。
之後看了一篇論文,這篇論文是我在大學第一篇關於多媒體領域的論文
然後教授要我們看這篇論文提出問題,
不管多簡單的問題都可以問,包括英文單字也可以問。
然後要我們做投影片報告這篇論文,然後指出作報告時的優缺點,
我喜歡這樣的上課方式,下次若有類似的課程,
我希望多發幾篇論文給學生看,做小組分工
然後上台報告的人接受底下的人問問題,是問問題、給意見而不是批判(評)
最好高年級跟低年級穿插在同一組
因為這樣學弟妹可以直接從學長姐身上學到作投影片的經驗,還有報告的經驗
這樣會更像做研究。
因為我覺得研究就是 抓住別人的缺點,掌握自己的優點
然後改善別人的缺點,增強自己的優點
我現在開始跟教授作研究了,我們報告的時候,教授和學長姐在下面問問題
我深覺一件事情: 教授也不是萬能的,他們也會問問題,他們也有問題
教授都有問題了,作為學生的,問問題的風氣和能力不應該比教授還要差
顏老師跟我說: 等你唸到博士碩士,已經不是老師交你了,而是反過來
你要去交老師,老師只給你一些方向和建議
這門課,教授在課堂上給我們看過一個影片 -- 地球是平的
那個影片的確也shock到我了,我大學所學的東西,
說實在的,在沒有複習的情況下,忘的一乾二淨,不記得學了些什麼
像影片所說的,只有不變的東西留下來-- 態度
我記得有一次上課,是要拿自己改進的投影片上台,
我想說我的投影片只有兩頁,實在是沒有什麼好改進的,
但是看到教授的投影片後,他說他改了一個禮拜,
圖都重新畫,我心中OS: 教授怎麼比學生還認真!!
這件事情給了我一個觀念,投影片要精心策劃,每一張投影片都要有功能
報告的時候要抓重點,怎麼抓重點需要學習
所以在未來研究所的課程裡,我立志論文中的圖能重畫盡量重畫
因為會比較清楚,而且可以加入動畫
以前有一個英文老師對我說: 上台就是一種表演,表演是一種藝術
而我認為,若上台報告是種表演,
在舞台上Focus住觀眾,也就是Focus住了Money
甚至讓觀眾很期待你的下一次表演。
這學期的資訊隱藏課程,上課方式我很喜歡,
我的優點是上課積極參與討論,經常私下和本泰可欣討論
出席狀況良好,沒有遲到過,BLOG 的篇數還可以
缺點是BLOG寫的不夠豐富,沒有寫程式,有一兩次缺席
對於課程內容了解與滿意,清楚課程目標
我給自己的分數是 70 分。
week16
問題1: 針對每一個經 DCT…
Ans:左上是低頻分部地方,越往右下則屬高頻,由黃老師本週對JPEG的解釋,image redundancy有三個主要原因,其中high frequency components,就是在說明眼睛看不清,頻率高,去表示就沒什麼意義,還要用很多bits數去表示,就是一種浪費,所以我想在做量化時,和一個特定量化矩陣相除,這一步驟為何越往右下,所要除的值就越大,就是為了相除之後的結果值越小,就可以用比較少的bits數,去儲存影像,而對低頻眼睛看的比較清,所以就需要較多bits去表示,更像原圖,所以特定量化矩陣左上的值才會比較小,才比較不會失真太多。
問題2: 量化後的係數矩陣中, 存在許多個0…
Ans:表示0的情形,因該是越往右下呈現越多這樣情形,因該是要減少高頻用過多bits數去儲存。
問題3: 用 Zigzag 的方式….
Ans:因該是為了電腦好處理,將二維轉換為一維,在轉成2進位表示方法,這樣就轉換成一長串10表示,進去給電腦處理;以Z字型排列,這樣的取係數方法,就等於從低頻慢慢取到高頻,高頻部分常常被量化成0所以就不用表示,只要看到EOB,因該也有個特定的2進位表示,電腦處理到這串位元,就知道後面皆為0了,一直取0將矩陣補齊成8*8,就可以代表出這個矩陣了,就不用在浪費多餘bits數,去表示後面皆是0的部分,來減少檔案大小。
問題4:為什麼JPEG壓縮…..
Ans:entropy coding就是壓縮的最後一步驟,不失真因該就是為了能再解壓縮回來,每個一長串2進位表示,皆是8*8矩陣,在相乘特定的量化矩陣回來,接的反離散餘弦轉換,在加128回來,就成為原初8*8影像;這部分有些許疑問,是不是圖片只有在第一次JPEG做編碼會失真而已,接下來怎麼壓縮跟解壓縮都不會在改變圖片了??我想因該是這樣,因為第一次做壓縮時,矩陣的係數已經算是被整理過一次,接下來再怎麼壓縮或解壓縮,係數再怎麼轉還是那些在轉換。
問題5:熵編碼(entropy coding)的熵所….
Ans:不知道網路上找的,定義離散無記憶資料源(discrete memoryless source, DMS),一個最簡單的資料源模型。
Ans:左上是低頻分部地方,越往右下則屬高頻,由黃老師本週對JPEG的解釋,image redundancy有三個主要原因,其中high frequency components,就是在說明眼睛看不清,頻率高,去表示就沒什麼意義,還要用很多bits數去表示,就是一種浪費,所以我想在做量化時,和一個特定量化矩陣相除,這一步驟為何越往右下,所要除的值就越大,就是為了相除之後的結果值越小,就可以用比較少的bits數,去儲存影像,而對低頻眼睛看的比較清,所以就需要較多bits去表示,更像原圖,所以特定量化矩陣左上的值才會比較小,才比較不會失真太多。
問題2: 量化後的係數矩陣中, 存在許多個0…
Ans:表示0的情形,因該是越往右下呈現越多這樣情形,因該是要減少高頻用過多bits數去儲存。
問題3: 用 Zigzag 的方式….
Ans:因該是為了電腦好處理,將二維轉換為一維,在轉成2進位表示方法,這樣就轉換成一長串10表示,進去給電腦處理;以Z字型排列,這樣的取係數方法,就等於從低頻慢慢取到高頻,高頻部分常常被量化成0所以就不用表示,只要看到EOB,因該也有個特定的2進位表示,電腦處理到這串位元,就知道後面皆為0了,一直取0將矩陣補齊成8*8,就可以代表出這個矩陣了,就不用在浪費多餘bits數,去表示後面皆是0的部分,來減少檔案大小。
問題4:為什麼JPEG壓縮…..
Ans:entropy coding就是壓縮的最後一步驟,不失真因該就是為了能再解壓縮回來,每個一長串2進位表示,皆是8*8矩陣,在相乘特定的量化矩陣回來,接的反離散餘弦轉換,在加128回來,就成為原初8*8影像;這部分有些許疑問,是不是圖片只有在第一次JPEG做編碼會失真而已,接下來怎麼壓縮跟解壓縮都不會在改變圖片了??我想因該是這樣,因為第一次做壓縮時,矩陣的係數已經算是被整理過一次,接下來再怎麼壓縮或解壓縮,係數再怎麼轉還是那些在轉換。
問題5:熵編碼(entropy coding)的熵所….
Ans:不知道網路上找的,定義離散無記憶資料源(discrete memoryless source, DMS),一個最簡單的資料源模型。
WEEK13 - PPT
看了LSB新方法那份paper後做出來的投影片
因為是遲交品所以沒能上台被電
我大概想講述的內容都打在備忘欄中
由於沒程式去DEMO
所以內容圖片都直接擷取paper內圖片
因此版面相對就簡陋許多
請多包含
投影片在此:PPT
因為是遲交品所以沒能上台被電
我大概想講述的內容都打在備忘欄中
由於沒程式去DEMO
所以內容圖片都直接擷取paper內圖片
因此版面相對就簡陋許多
請多包含
投影片在此:PPT
2007年6月14日 星期四
WEEK15 JPEG問題
上禮拜有點累倒所以沒去上課
這次就看了一下上週的進度然後來寫寫這些問題
當然...主要是查來的資料看一看整理一下
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
ANS:(1)使用一組值來代表顏色的數學模型
(2)因為有不同的方法來代表色彩空間
例如RGB(三原色)三色形成的色彩空間、HSB(色調、飽和度、亮度)形成的色彩空間等,所以會有不同的表示
(3)例如RGB色彩空間是基於光學設備採用的方式
但假如我們想把圖像印出來時,需要使用CMYK色彩空間
這時候,我們就需要色彩空間的轉換
2. 什麼是量化? 好處是什麼?
ANS: (1)將類似的數值取出來減少重覆的數據量
(2)好處可以減少圖像的數據量,選擇性的丟棄部分數據作為壓縮
3. 什麼是轉換? 為什麼要做 DCT 轉換?
ANS: (1)應該和色彩空間的轉換那種概念差不多...
我也不太會描述
(2)就是要讓矩陣的"能量集中"
可以造成比較沒有失真的感覺
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
ANS: (1)轉換後會讓能量集中在左上角,有更大的壓縮空間
(2)(3)雖然常常看到JPEG的技術有低頻和高頻這詞...
不過都沒啥說明
大致上就是壓縮的時候,圖像經濾波分成若干個低頻和高頻的分量
大致是二維的
(4)這個真的不太清楚...也許要再找找資料
這次就看了一下上週的進度然後來寫寫這些問題
當然...主要是查來的資料看一看整理一下
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
ANS:(1)使用一組值來代表顏色的數學模型
(2)因為有不同的方法來代表色彩空間
例如RGB(三原色)三色形成的色彩空間、HSB(色調、飽和度、亮度)形成的色彩空間等,所以會有不同的表示
(3)例如RGB色彩空間是基於光學設備採用的方式
但假如我們想把圖像印出來時,需要使用CMYK色彩空間
這時候,我們就需要色彩空間的轉換
2. 什麼是量化? 好處是什麼?
ANS: (1)將類似的數值取出來減少重覆的數據量
(2)好處可以減少圖像的數據量,選擇性的丟棄部分數據作為壓縮
3. 什麼是轉換? 為什麼要做 DCT 轉換?
ANS: (1)應該和色彩空間的轉換那種概念差不多...
我也不太會描述
(2)就是要讓矩陣的"能量集中"
可以造成比較沒有失真的感覺
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
ANS: (1)轉換後會讓能量集中在左上角,有更大的壓縮空間
(2)(3)雖然常常看到JPEG的技術有低頻和高頻這詞...
不過都沒啥說明
大致上就是壓縮的時候,圖像經濾波分成若干個低頻和高頻的分量
大致是二維的
(4)這個真的不太清楚...也許要再找找資料
week15 -- (JPEG)
嗯...寫的不多...若寫的有問題...請不吝指教...
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
由R,G,B或WIKI中提到的YUV都是色彩空間的一種,他們都可以形容色彩,只是組成的基本東西不同,描述顏色的方式不同罷了!
因為每種色彩空間所能夠描述的顏色及方法都不同,每種色彩空間的區域並不會完全一致。
要看需求來選擇轉換色彩空間。
2. 什麼是量化? 好處是什麼?
將複雜的東西轉化為數字,讓我們比較容易了解,並進而使用它。
好處是會使複雜的東西簡單化,變的較好處理。
3. 什麼是轉換? 為什麼要做 DCT 轉換?
嗯...不太會說...
為了要轉換到頻率空間,這樣才可以看的比較清楚,較清楚空間的內容。
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
意義...嗯...
頻率:等於週期的倒數,若你做完一個週期的時間長,那麼你的頻率就相對的短(低),若你花很少時間做完一個週期,那麼頻率就高。
對應後...低頻是相鄰的像素變化率不大,高頻是相鄰的像素變化率大的意思。大約都低頻...畫面是漸漸的、緩慢的變化。
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
由R,G,B或WIKI中提到的YUV都是色彩空間的一種,他們都可以形容色彩,只是組成的基本東西不同,描述顏色的方式不同罷了!
因為每種色彩空間所能夠描述的顏色及方法都不同,每種色彩空間的區域並不會完全一致。
要看需求來選擇轉換色彩空間。
2. 什麼是量化? 好處是什麼?
將複雜的東西轉化為數字,讓我們比較容易了解,並進而使用它。
好處是會使複雜的東西簡單化,變的較好處理。
3. 什麼是轉換? 為什麼要做 DCT 轉換?
嗯...不太會說...
為了要轉換到頻率空間,這樣才可以看的比較清楚,較清楚空間的內容。
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
意義...嗯...
頻率:等於週期的倒數,若你做完一個週期的時間長,那麼你的頻率就相對的短(低),若你花很少時間做完一個週期,那麼頻率就高。
對應後...低頻是相鄰的像素變化率不大,高頻是相鄰的像素變化率大的意思。大約都低頻...畫面是漸漸的、緩慢的變化。
2007年6月13日 星期三
Week 9 : Paper 心得
這個禮拜,我們看一篇Paper,並寫下心得。
我的第一個問題是: 如果closest color很多,但是卻剛好沒有parity
這種情況是有可能會發生的。
第二種情況剛好相反,Parity很多,但是都是不相似的顏色
這種情況也是有可能發生的。
第三個問題是,兩種不同顏色,是否有可能會有同一組closest color且parity 一樣
經過老師講解後,第一個問題始有可能會發生,但是機率很小。
第二種情況也有可能會發生。重點不是(R+G+B)mod 2這個公式
事實上我們也可以用別的公式來產生Parity,
但是我們希望找顏色最接近的來當Parity
第三個問題,答案是會有這種情況的。
我的第一個問題是: 如果closest color很多,但是卻剛好沒有parity
這種情況是有可能會發生的。
第二種情況剛好相反,Parity很多,但是都是不相似的顏色
這種情況也是有可能發生的。
第三個問題是,兩種不同顏色,是否有可能會有同一組closest color且parity 一樣
經過老師講解後,第一個問題始有可能會發生,但是機率很小。
第二種情況也有可能會發生。重點不是(R+G+B)mod 2這個公式
事實上我們也可以用別的公式來產生Parity,
但是我們希望找顏色最接近的來當Parity
第三個問題,答案是會有這種情況的。
week13: PPT Design (2)
今天上課的目的,要我們把上次的PPT經過修改
再Present一次,我的雖然有改,但是我卻不太想上台
因為我覺得實在是沒有什麼好講的
我的投影片只有兩頁,我只有把版面稍微調的漂亮一點而已
因為我已經做的很精簡了,再精簡可能沒辦法了。
只能往別的地方發展。
投影片放在網路硬碟上: webhd.mcu.edu.tw
分享名稱: IMH Class
雖然當初會有這樣的想法,但是看到老師修改的投影片後
覺得自己有點弱了
蓮老師都那麼認真的再作投影片,我怎麼能鬆懈呢?
而且又製作動畫,加上所有的圖都自己重新再畫。
我最近也開始要報告了,我看到我學長他們做的投影片
和老師做的投影片,比較起來,真的可以看的出來有沒有用心在報告
後來我做投影片開始把圖重新畫,加上動畫
一篇論文有很多東西,在三小時內,我應該要報告哪些東西,
我覺得這是一件困難的事情,是我還需要去學習的。
再Present一次,我的雖然有改,但是我卻不太想上台
因為我覺得實在是沒有什麼好講的
我的投影片只有兩頁,我只有把版面稍微調的漂亮一點而已
因為我已經做的很精簡了,再精簡可能沒辦法了。
只能往別的地方發展。
投影片放在網路硬碟上: webhd.mcu.edu.tw
分享名稱: IMH Class
雖然當初會有這樣的想法,但是看到老師修改的投影片後
覺得自己有點弱了
蓮老師都那麼認真的再作投影片,我怎麼能鬆懈呢?
而且又製作動畫,加上所有的圖都自己重新再畫。
我最近也開始要報告了,我看到我學長他們做的投影片
和老師做的投影片,比較起來,真的可以看的出來有沒有用心在報告
後來我做投影片開始把圖重新畫,加上動畫
一篇論文有很多東西,在三小時內,我應該要報告哪些東西,
我覺得這是一件困難的事情,是我還需要去學習的。
week12 : PPT Design (Part 1)
這禮拜老師要我們把論文製作成PPT
老師把高年級的與低年級的分開,來比較投影片的製作
我負責的是最後一段 Conclusion
我的投影片放在: wehd.mcu.edu.tw
分享名稱為: IMH Class
今天上課很開心,還有拍照。
不過Conclusion對我來說,算是比較簡單。
難報告的都讓其他人挑走了。
老師把高年級的與低年級的分開,來比較投影片的製作
我負責的是最後一段 Conclusion
我的投影片放在: wehd.mcu.edu.tw
分享名稱為: IMH Class
今天上課很開心,還有拍照。
不過Conclusion對我來說,算是比較簡單。
難報告的都讓其他人挑走了。
Week 2 : Introduce to Steganography Tool : S-Tools
本文主要是介紹藏匿工具中的一套軟體: S-Tools 的操作。
S-Tools 的 S 所代表的英文單字是Steganography(藏匿)的意思。
目前市面上有很多的藏匿工具。S-Tools 可以將訊息嵌入到 GIF格式 的影像中。
本文的用意在於簡單描述其中一套藏匿工具 S-Tools 的操作。(請按此下載 S-Tools )
請按此下載 S-Tools 的使用說明檔案。
S-Tools 的 S 所代表的英文單字是Steganography(藏匿)的意思。
目前市面上有很多的藏匿工具。S-Tools 可以將訊息嵌入到 GIF格式 的影像中。
本文的用意在於簡單描述其中一套藏匿工具 S-Tools 的操作。(請按此下載 S-Tools )
請按此下載 S-Tools 的使用說明檔案。
Week1 : Introduction to Information Hiding
隨著網路網路(Internet)的蓬勃發展,人們開始藉由網路隨送資料或檔案,但是這樣的一個網路機制,必須要建立在一個具有安全性(Security)的網路上面。試想,若網路傳輸少了安全性,還剩下些什麼 ? 當甲方傳送明文(Plain Text)給乙方時,甲方無法確認該資料是否真的由乙方傳送 ? 在這傳送的過程中,資料是否還完整 ? 資料在傳送途中,如何保證不受到第三者的竊聽與竄改 ?
為了確保明文在傳送過程中,不被第三者竊聽與竄改,於是人們運用密碼學(Cryptography)對明文加密(Encryption),使之變成密文(Cipher Text),通常使明文變的不可讀(non-readable),故此倘若第三者從網路上竊取了傳送端(Sender)所傳送的資料,也無法得知內容。對於情報工作者而言,保密情報是一件非常重要的事情。密碼學Cryptography這單字中,Crypto- 是指secret 的意思,而graph有writing的意思。
在1996年前,相較於密碼學,藏匿學(Steganography)的技術始終受到業界(Industry)及學界(Research Community)比較少的關注。然而隨著多媒體(Multimedia)技術的發展,人們可以輕易的複製這些數位媒體(Digital Media),例如:文字檔(Text)、圖形(Image)、聲音(Audio)、視訊(Video)等,而造成了版權上的問題。由於數位媒體有完整複製(Perfect Copy)的特性,使得不肖業者,可能會未經版權所有者的認可,大量複製(Large-scale Unauthorized Copy)這些數位媒體。對於創作者或版權所有者造成莫大的影響。於是有人想出,把關於著作權的資訊,內嵌(Embedding)於這些數位媒體當中。當數位媒體被複製時,內嵌的著作權資訊也一併被複製了,便於作者對於著作權的追溯。
這和多媒體的進步,有很大的關係。就拿聲音來說好了,過去傳統的聲音是紀錄於錄音帶(tape)中,只能用錄音的方式來複製,而這樣的複製,將會使複製出來的音質產生誤差。換言之,若複製過後的錄音帶,再經過一次複製,將會使複製出來的音質產生更大的誤差,造成失真的現象。而現在儲存音樂大部分是採用數位形式(Digital Form)來儲存,例如:CD(Compact Disc)。當我們燒錄CD或DVD、VCD時,都能夠完整燒錄,並且不失真。
將資訊隱藏(Information Hiding)的這個想法,並非是近代科學才有,而是從以前就有人這樣作了。例如在兩千多年前的古希臘時代,就有人刮除平時書寫用的小臘版,將信息刻在木板上,再重新用蠟封起來,順利通過邊境檢查,送至斯巴達王后手中,王后將蠟除去後,得知戰爭即將來臨的訊息。而在中國也有類似的觀念,例如江南四大才子之一的唐伯虎,在他的著作 – 西江月中,以每個詩句的字首暗喻進入華府為奴僕是為了秋香。
唐伯虎‧西江月
我聞西方大士,為人了卻凡心。秋來明月照蓬門,香滿禪房出徑。
屈指靈山會後,居然紫竹成林。童男童女拜觀音,僕僕何嫌榮頓。
內嵌:〔我為秋香屈居童僕。〕
這樣的著作,在中國稱為內嵌詩,也有著資訊隱藏的概念。可見資訊隱藏除了要隱藏的資訊外,還需要隱藏的媒體,這樣的媒體我們稱為掩護媒體(Cover Media),掩護媒體經嵌入資訊後變成一份偽裝媒體 (stego-media)。若我們仔細看Steganography這個單字,Stegano- 有掩護遮蔽的意思,而則有graph有writing的意思,最早可追溯到古希臘時代。
然而大部分的人對於密碼學和藏匿學容易感到混淆。密碼學主要是在探討將如何將明文經過加密演算法後變為密文,而這個密文要讓除了傳送端與接收端以外的第三者無法推敲出原來的明文。希望明文經過加密後,越讓人經由密文猜測出原來的明文。而藏匿學則是藉由掩護媒體,將需要藏匿的資訊隱藏在媒體中,讓人無法察覺被藏匿的資訊。
舉一個例子來說好了,當甲和乙在網路上進行秘密通訊時,甲將明文加密為密文,之後經由網路傳送給乙。雖然第三者無法得知假傳給了乙什麼樣的訊息,但是藉由亂七八糟的密文可以得知,甲和乙在作秘密通訊。秘密通訊這件事情是容易被察覺的。若甲將密文內嵌於其他媒體上,例如圖片,再經由網路傳送內嵌著資訊的圖片給乙,第三者可以得知甲乙在作通訊,但是第三者會認為,這只是普通的圖片傳輸,沒有什麼秘密通訊的成分在裡面。
相較於直接加密,資訊隱藏的方法更具有保密的作用。將欲保密的資料先經過加密的動作,再隱藏於掩護媒體中,則保密效果更好,如同上了兩層鎖的保險櫃一樣。
在2001年的911事件之前,有人謠傳賓拉登和其他恐怖份子,利用資訊隱藏軟體隱藏恐怖活動的訊息。他們在網路的休閒聊天室,色情佈告欄,其他網站等貼上恐怖攻擊目標的圖片。試想美國的聯邦調查局(FBI)該如何查出這些掩護媒體呢? 張貼的圖片那麼多張,究竟哪一張才是具有嵌入祕密資訊的圖片呢? 還有那麼多人瀏覽過這些圖片,究竟這些瀏覽圖片的人當中,哪些才是賓拉登的黨羽呢? 這是一個難度很高的挑戰。
為了確保明文在傳送過程中,不被第三者竊聽與竄改,於是人們運用密碼學(Cryptography)對明文加密(Encryption),使之變成密文(Cipher Text),通常使明文變的不可讀(non-readable),故此倘若第三者從網路上竊取了傳送端(Sender)所傳送的資料,也無法得知內容。對於情報工作者而言,保密情報是一件非常重要的事情。密碼學Cryptography這單字中,Crypto- 是指secret 的意思,而graph有writing的意思。
在1996年前,相較於密碼學,藏匿學(Steganography)的技術始終受到業界(Industry)及學界(Research Community)比較少的關注。然而隨著多媒體(Multimedia)技術的發展,人們可以輕易的複製這些數位媒體(Digital Media),例如:文字檔(Text)、圖形(Image)、聲音(Audio)、視訊(Video)等,而造成了版權上的問題。由於數位媒體有完整複製(Perfect Copy)的特性,使得不肖業者,可能會未經版權所有者的認可,大量複製(Large-scale Unauthorized Copy)這些數位媒體。對於創作者或版權所有者造成莫大的影響。於是有人想出,把關於著作權的資訊,內嵌(Embedding)於這些數位媒體當中。當數位媒體被複製時,內嵌的著作權資訊也一併被複製了,便於作者對於著作權的追溯。
這和多媒體的進步,有很大的關係。就拿聲音來說好了,過去傳統的聲音是紀錄於錄音帶(tape)中,只能用錄音的方式來複製,而這樣的複製,將會使複製出來的音質產生誤差。換言之,若複製過後的錄音帶,再經過一次複製,將會使複製出來的音質產生更大的誤差,造成失真的現象。而現在儲存音樂大部分是採用數位形式(Digital Form)來儲存,例如:CD(Compact Disc)。當我們燒錄CD或DVD、VCD時,都能夠完整燒錄,並且不失真。
將資訊隱藏(Information Hiding)的這個想法,並非是近代科學才有,而是從以前就有人這樣作了。例如在兩千多年前的古希臘時代,就有人刮除平時書寫用的小臘版,將信息刻在木板上,再重新用蠟封起來,順利通過邊境檢查,送至斯巴達王后手中,王后將蠟除去後,得知戰爭即將來臨的訊息。而在中國也有類似的觀念,例如江南四大才子之一的唐伯虎,在他的著作 – 西江月中,以每個詩句的字首暗喻進入華府為奴僕是為了秋香。
唐伯虎‧西江月
我聞西方大士,為人了卻凡心。秋來明月照蓬門,香滿禪房出徑。
屈指靈山會後,居然紫竹成林。童男童女拜觀音,僕僕何嫌榮頓。
內嵌:〔我為秋香屈居童僕。〕
這樣的著作,在中國稱為內嵌詩,也有著資訊隱藏的概念。可見資訊隱藏除了要隱藏的資訊外,還需要隱藏的媒體,這樣的媒體我們稱為掩護媒體(Cover Media),掩護媒體經嵌入資訊後變成一份偽裝媒體 (stego-media)。若我們仔細看Steganography這個單字,Stegano- 有掩護遮蔽的意思,而則有graph有writing的意思,最早可追溯到古希臘時代。
然而大部分的人對於密碼學和藏匿學容易感到混淆。密碼學主要是在探討將如何將明文經過加密演算法後變為密文,而這個密文要讓除了傳送端與接收端以外的第三者無法推敲出原來的明文。希望明文經過加密後,越讓人經由密文猜測出原來的明文。而藏匿學則是藉由掩護媒體,將需要藏匿的資訊隱藏在媒體中,讓人無法察覺被藏匿的資訊。
舉一個例子來說好了,當甲和乙在網路上進行秘密通訊時,甲將明文加密為密文,之後經由網路傳送給乙。雖然第三者無法得知假傳給了乙什麼樣的訊息,但是藉由亂七八糟的密文可以得知,甲和乙在作秘密通訊。秘密通訊這件事情是容易被察覺的。若甲將密文內嵌於其他媒體上,例如圖片,再經由網路傳送內嵌著資訊的圖片給乙,第三者可以得知甲乙在作通訊,但是第三者會認為,這只是普通的圖片傳輸,沒有什麼秘密通訊的成分在裡面。
相較於直接加密,資訊隱藏的方法更具有保密的作用。將欲保密的資料先經過加密的動作,再隱藏於掩護媒體中,則保密效果更好,如同上了兩層鎖的保險櫃一樣。
在2001年的911事件之前,有人謠傳賓拉登和其他恐怖份子,利用資訊隱藏軟體隱藏恐怖活動的訊息。他們在網路的休閒聊天室,色情佈告欄,其他網站等貼上恐怖攻擊目標的圖片。試想美國的聯邦調查局(FBI)該如何查出這些掩護媒體呢? 張貼的圖片那麼多張,究竟哪一張才是具有嵌入祕密資訊的圖片呢? 還有那麼多人瀏覽過這些圖片,究竟這些瀏覽圖片的人當中,哪些才是賓拉登的黨羽呢? 這是一個難度很高的挑戰。
Week15上課筆記
編碼
色彩轉換空間
將影像由RGB轉成YUV(Y:一個像素的亮度,U和V:調色與飽和度)的不同色彩空間,一般的色彩空間由RGB所組成,我們將他轉換成另一種色彩空間YUV,因為人類的眼睛對於亮度看的比調色和飽和度看的更仔細,所以運用YUV的色彩空間讓影像壓縮更有效率
縮減取樣
減少U和V的取樣
離散餘弦變換(DCT)
座標轉換:根據資料特性發展出一套新的座標系統,以減少資料儲存的數量或者是資料比較好被描述
轉換後的座標,左上角就是DC係數(整個亮度的平均值)
量化
將想要表現的東西以數字表現出來
人類對於高頻率的東西,分辨的能力不是很好,所以我們可以運用高頻率降低資訊的數量
轉換後的DCT係數矩陣跟一個量化矩陣作運算,運算後的矩陣會出現蠻明顯的差異
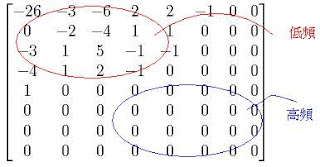
低頻:相鄰兩像素的變化率不大
高頻:相鄰兩像素的變化率大
色彩轉換空間
將影像由RGB轉成YUV(Y:一個像素的亮度,U和V:調色與飽和度)的不同色彩空間,一般的色彩空間由RGB所組成,我們將他轉換成另一種色彩空間YUV,因為人類的眼睛對於亮度看的比調色和飽和度看的更仔細,所以運用YUV的色彩空間讓影像壓縮更有效率
縮減取樣
減少U和V的取樣
離散餘弦變換(DCT)
座標轉換:根據資料特性發展出一套新的座標系統,以減少資料儲存的數量或者是資料比較好被描述
轉換後的座標,左上角就是DC係數(整個亮度的平均值)
量化
將想要表現的東西以數字表現出來
人類對於高頻率的東西,分辨的能力不是很好,所以我們可以運用高頻率降低資訊的數量
轉換後的DCT係數矩陣跟一個量化矩陣作運算,運算後的矩陣會出現蠻明顯的差異

低頻:相鄰兩像素的變化率不大
高頻:相鄰兩像素的變化率大
2007年6月11日 星期一
Week15 JPEG
把老師所提的問題
在經過整理過後
以自己的口吻回答
我覺得我答的不是很好
請大家多多指教
找出我的問題
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
Ans1:
一群顏色的集合即可稱為色彩空間
Ans2:
不同的色彩空間代表用不同的條件
來形容一群色彩的集合
例如RGB是用紅藍綠三色各佔多少來形容一種顏色
而YCbCr卻是用亮度、色差與飽和度來表達一種顏色
由此可知雖然描述的條件不同卻可同樣用來形容一群顏色
Ans3:
看使用者的需求
像是印表機使用的色彩空間是YMCK
即是一個很好的例子
試想用RGB要怎麼表達出來黑色呢?
2. 什麼是量化? 好處是什麼?
Ans1:
量化即是把一種現象或想描述的事情用數量的形式來表現
Ans2:
可使數據的結果更簡潔
方便觀察或者簡化
3. 什麼是轉換? 為什麼要做 DCT 轉換?
Ans1:
其實轉換的概念我覺得跟色彩空間的轉換概念很像
也是以不同的方式來描述的一群東西的集合
例如要表達平面上的一條線常使用的方法為
y=ax+b
但這個表達是有缺陷的
因為無法表達垂直的角度
因此有人提出了不同的方法
來形容一條線
r = x.cosθ + y.sinθ
這就是一種轉換
而其實這兩個方程式
都是在描述一條線!
Ans2:
因為離散餘弦變換具有很強的"能量集中"特性大多數的自然信號
(包括聲音和圖像)的能量都集中在離散餘弦變換後的低頻部分
所以從講義的8*8陣列可以發現
大部分的頻率都集中到右上角去了
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
Ans1:
會有低頻集中在左上角
高頻散佈在右下角的特性
Ans2:
Ans3:
Ans4:
在經過整理過後
以自己的口吻回答
我覺得我答的不是很好
請大家多多指教
找出我的問題
1. 什麼是色彩空間? 為什麼有不同的色彩空間? 轉換的目的為何?
Ans1:
一群顏色的集合即可稱為色彩空間
Ans2:
不同的色彩空間代表用不同的條件
來形容一群色彩的集合
例如RGB是用紅藍綠三色各佔多少來形容一種顏色
而YCbCr卻是用亮度、色差與飽和度來表達一種顏色
由此可知雖然描述的條件不同卻可同樣用來形容一群顏色
Ans3:
看使用者的需求
像是印表機使用的色彩空間是YMCK
即是一個很好的例子
試想用RGB要怎麼表達出來黑色呢?
2. 什麼是量化? 好處是什麼?
Ans1:
量化即是把一種現象或想描述的事情用數量的形式來表現
Ans2:
可使數據的結果更簡潔
方便觀察或者簡化
3. 什麼是轉換? 為什麼要做 DCT 轉換?
Ans1:
其實轉換的概念我覺得跟色彩空間的轉換概念很像
也是以不同的方式來描述的一群東西的集合
例如要表達平面上的一條線常使用的方法為
y=ax+b
但這個表達是有缺陷的
因為無法表達垂直的角度
因此有人提出了不同的方法
來形容一條線
r = x.cosθ + y.sinθ
這就是一種轉換
而其實這兩個方程式
都是在描述一條線!
Ans2:
因為離散餘弦變換具有很強的"能量集中"特性大多數的自然信號
(包括聲音和圖像)的能量都集中在離散餘弦變換後的低頻部分
所以從講義的8*8陣列可以發現
大部分的頻率都集中到右上角去了
4. DCT 轉換後的矩陣的意義為何? 何謂低頻? 何謂高頻? 對應到一張影像所呈現的意義是什麼?
Ans1:
會有低頻集中在左上角
高頻散佈在右下角的特性
Ans2:
Ans3:
Ans4:
2007年6月9日 星期六
Weak 15 - jpeg
關於jpeg的隱藏技術
由於目前我在做的專研是關於視覺密碼的部份
所以先前也讀了些關於jpeg隱藏浮水印的方法
首先相對於之前的bmp檔案
jpeg檔案是壓縮後的圖像
所以最低位元是壓縮時首先被捨棄掉的部份
(因為最低位元的影像雜亂,捨棄後對原圖沒太大影響)
由於最低位元被捨棄掉了
所以先前所使用的LSB則不適用
再來我要提到空間域及頻率域的技術
空間域:
空間域就是指我們平常圖像用bitmap紀錄的方式
而先前提到的LSB就屬於空間域的技術
但是在jpeg中我們並無法使用LSB來隱藏資訊
因此既然我們無法將資訊隱藏在最低位元中
我們則求其次將資訊隱藏在中頻帶
(由於壓縮影像的資訊隱藏,我們都是先轉至頻率域找出適合隱藏的地方,
然後再轉回空間域,但是在此利用影像四元樹的方法則無須經過此轉換即
可找出中低頻位址,至於頻帶所代表的涵義,我會在頻率域的部份做解釋)
如此一來便能在影響原圖的最低限度下藏入資訊
頻率域:
最簡單的想法,我們將它想成音頻
大概就是長的像那樣的東西
至於我們要如何將空間域的圖片轉換成頻率域
主要是使用以下三種轉換方式:
1.離散餘弦轉換
2.離散小波轉換
3.快速傅立葉轉換
(其轉換公式在此就不詳述,否則真會打不完)
藉由以上方法我們就能將空間域的圖片轉換成頻率域
在頻率域中,我們分成高頻帶、中頻帶、低頻帶三個部份
低頻帶就像是空間域中的最高位元
高頻帶則代表最低位元
由於之前提到最低位元是jpeg影像最優先捨去的部份
所以資訊不能藏在高頻帶
而低頻帶影響圖片最大,所以也不能藏在低頻帶
因此我們所能藏匿的地方就只剩中頻帶了
以上大致就是jpeg這類壓縮圖象隱藏資訊時所用的技術
至於更細節的部分在此也不多詳述
參考論文:
沈伯承-民國92年,中央大學碩士論文,基於灰階視覺密碼之浮水印技術
由於目前我在做的專研是關於視覺密碼的部份
所以先前也讀了些關於jpeg隱藏浮水印的方法
首先相對於之前的bmp檔案
jpeg檔案是壓縮後的圖像
所以最低位元是壓縮時首先被捨棄掉的部份
(因為最低位元的影像雜亂,捨棄後對原圖沒太大影響)
由於最低位元被捨棄掉了
所以先前所使用的LSB則不適用
再來我要提到空間域及頻率域的技術
空間域:
空間域就是指我們平常圖像用bitmap紀錄的方式
而先前提到的LSB就屬於空間域的技術
但是在jpeg中我們並無法使用LSB來隱藏資訊
因此既然我們無法將資訊隱藏在最低位元中
我們則求其次將資訊隱藏在中頻帶
(由於壓縮影像的資訊隱藏,我們都是先轉至頻率域找出適合隱藏的地方,
然後再轉回空間域,但是在此利用影像四元樹的方法則無須經過此轉換即
可找出中低頻位址,至於頻帶所代表的涵義,我會在頻率域的部份做解釋)
如此一來便能在影響原圖的最低限度下藏入資訊
頻率域:
最簡單的想法,我們將它想成音頻
大概就是長的像那樣的東西
至於我們要如何將空間域的圖片轉換成頻率域
主要是使用以下三種轉換方式:
1.離散餘弦轉換
2.離散小波轉換
3.快速傅立葉轉換
(其轉換公式在此就不詳述,否則真會打不完)
藉由以上方法我們就能將空間域的圖片轉換成頻率域
在頻率域中,我們分成高頻帶、中頻帶、低頻帶三個部份
低頻帶就像是空間域中的最高位元
高頻帶則代表最低位元
由於之前提到最低位元是jpeg影像最優先捨去的部份
所以資訊不能藏在高頻帶
而低頻帶影響圖片最大,所以也不能藏在低頻帶
因此我們所能藏匿的地方就只剩中頻帶了
以上大致就是jpeg這類壓縮圖象隱藏資訊時所用的技術
至於更細節的部分在此也不多詳述
參考論文:
沈伯承-民國92年,中央大學碩士論文,基於灰階視覺密碼之浮水印技術
2007年6月8日 星期五
week15
這週換開始討論jpeg,其實想法因該還是滿不清楚的,就先寫段文章順便統整一下想法,下週觀念要是更清楚點,在改正了,有錯也請回應告知~謝謝
首先,色彩空間轉換
就如同老師講的 不同的運用 就會有不同的方法去表示 即jpeg就用YUV方法,去表示色彩空間
接的,縮減取樣
利用對色調和飽和度,眼睛對此沒有這麼高的靈敏度 所以就減少這方面的資料 來達到 縮減檔案的目的,原先以為要是採無縮減取樣的方法,那圖片不就不會失真了,後來去問老師才知此step雖不失真,但經過DC轉換後還是會失真
DCT
太過於數學 所以就沒什麼討論,左上角是數值最大的,我猜是為了知道什麼數值最大是什麼,就知道這圖檔,最長是用幾bits去表示,就不會多浪費更多bits數去紀錄,而顯示的都是0,浪費檔案空間
量化
圖片經過DC轉換後,所得到的矩陣在去跟一個受過設計的量化矩陣各別位置皆去相除,這樣所出來的矩陣,每個數值就都別具有意義,8*8這樣即有64量化矩陣等待處理,至於矩陣左上為何皆低頻,右下皆高頻居多,那天聽的滿模糊的,大概寫一下現在想法,文章有談到,人對高頻率辨識能力比較差,所以可以在那降低資訊數量,來縮減檔案,所以這就為何右下高頻部分會皆0居多,原因就是資料被裁減掉,而對低頻辨識能力比較好點,所以就相對需要更多資訊數量去紀錄表示,來讓畫面呈現更像原圖, 所以猜想左上到右下,數值會越來越偏向0因該就是這樣,而左上低頻右下高頻,就可能跟老師講的這矩陣是受過設計的,所以分布才呈現這樣
顏色越相鄰DC值越強,老師有舉例白色,同顏色所以皆相鄰在一起,DC值很大,其餘皆是0,因為這是高頻率的顏色;這樣要是換用低頻率的單一顏色,因還是皆相鄰在一起,DC值還是一樣大,而且是低頻,不能去裁減掉很多資訊,這樣檔案不就比較大嗎???所以高頻率亮度變動,是指顏色的頻率,還是顏色間變動的頻率,這點就滿不清楚的
後來自己用小畫家去做測試,儲存全紫跟全紅的jpeg圖案,發現兩邊檔案大小相同皆是3.61KB,後來在做一張圖,紫跟紅相間的圖案檔案就大很多是576KB,所以高頻率變動是指顏色間變動的頻率,所以同顏色間都沒有變動,這屬於低頻,所以低頻部分特高,所以DC才會特別大,越往右下是高頻部分,因都低頻沒有高頻所以才都是0,是這樣嗎???但既然是低頻,這樣資訊就不能減掉很多,這樣資訊裡因該很多位置都要有值去紀錄阿,怎會這麼多0,所以是上面低頻跟高頻有分開看,還是下面觀念是這正確,還是都錯誤,老師下週可以的話,可以說明一下,同顏色的矩陣裡為何是這樣,今天寫到這 越想越亂= =
首先,色彩空間轉換
就如同老師講的 不同的運用 就會有不同的方法去表示 即jpeg就用YUV方法,去表示色彩空間
接的,縮減取樣
利用對色調和飽和度,眼睛對此沒有這麼高的靈敏度 所以就減少這方面的資料 來達到 縮減檔案的目的,原先以為要是採無縮減取樣的方法,那圖片不就不會失真了,後來去問老師才知此step雖不失真,但經過DC轉換後還是會失真
DCT
太過於數學 所以就沒什麼討論,左上角是數值最大的,我猜是為了知道什麼數值最大是什麼,就知道這圖檔,最長是用幾bits去表示,就不會多浪費更多bits數去紀錄,而顯示的都是0,浪費檔案空間
量化
圖片經過DC轉換後,所得到的矩陣在去跟一個受過設計的量化矩陣各別位置皆去相除,這樣所出來的矩陣,每個數值就都別具有意義,8*8這樣即有64量化矩陣等待處理,至於矩陣左上為何皆低頻,右下皆高頻居多,那天聽的滿模糊的,大概寫一下現在想法,文章有談到,人對高頻率辨識能力比較差,所以可以在那降低資訊數量,來縮減檔案,所以這就為何右下高頻部分會皆0居多,原因就是資料被裁減掉,而對低頻辨識能力比較好點,所以就相對需要更多資訊數量去紀錄表示,來讓畫面呈現更像原圖, 所以猜想左上到右下,數值會越來越偏向0因該就是這樣,而左上低頻右下高頻,就可能跟老師講的這矩陣是受過設計的,所以分布才呈現這樣
顏色越相鄰DC值越強,老師有舉例白色,同顏色所以皆相鄰在一起,DC值很大,其餘皆是0,因為這是高頻率的顏色;這樣要是換用低頻率的單一顏色,因還是皆相鄰在一起,DC值還是一樣大,而且是低頻,不能去裁減掉很多資訊,這樣檔案不就比較大嗎???所以高頻率亮度變動,是指顏色的頻率,還是顏色間變動的頻率,這點就滿不清楚的
後來自己用小畫家去做測試,儲存全紫跟全紅的jpeg圖案,發現兩邊檔案大小相同皆是3.61KB,後來在做一張圖,紫跟紅相間的圖案檔案就大很多是576KB,所以高頻率變動是指顏色間變動的頻率,所以同顏色間都沒有變動,這屬於低頻,所以低頻部分特高,所以DC才會特別大,越往右下是高頻部分,因都低頻沒有高頻所以才都是0,是這樣嗎???但既然是低頻,這樣資訊就不能減掉很多,這樣資訊裡因該很多位置都要有值去紀錄阿,怎會這麼多0,所以是上面低頻跟高頻有分開看,還是下面觀念是這正確,還是都錯誤,老師下週可以的話,可以說明一下,同顏色的矩陣裡為何是這樣,今天寫到這 越想越亂= =
week2
利用s-tool工具
可將圖片格式為BMP和GIF檔,以及音效格式為WMV檔
當作是要隱藏資訊的檔案 遷入到不相干的圖片中 去隱藏這些訊息,
也可以加密,要有密碼的人 才會解密 得到 此圖裡 隱藏的另一個訊息
假如你要藏的 資訊過大 大到無法 遷入到那圖片中 系統就會顯示訊息
說明無法將此圖 資訊 藏到此檔案裡
但發現 遷入訊息前跟後 圖片的亮度會有所差異
前者較為明亮鮮豔點 後者較為暗淡
可能是從256色降至32色
然後在將欲隱藏的訊息分別遷入像素的各R、G、B最後一位元裡,
每個位元都有兩種可能 一種就是原本相同不用改變 一種就是不同
需要改成要隱藏訊息的位元,所以就在可變可不變之下最多差異是
2*2*2=8,最多情況就是到<=256色情況,所以可利用的顏色數大多
不如原先256色多,大多情形 在遷入隱藏訊息之後呈現的圖片,
才比較黯淡。
可將圖片格式為BMP和GIF檔,以及音效格式為WMV檔
當作是要隱藏資訊的檔案 遷入到不相干的圖片中 去隱藏這些訊息,
也可以加密,要有密碼的人 才會解密 得到 此圖裡 隱藏的另一個訊息
假如你要藏的 資訊過大 大到無法 遷入到那圖片中 系統就會顯示訊息
說明無法將此圖 資訊 藏到此檔案裡
但發現 遷入訊息前跟後 圖片的亮度會有所差異
前者較為明亮鮮豔點 後者較為暗淡
可能是從256色降至32色
然後在將欲隱藏的訊息分別遷入像素的各R、G、B最後一位元裡,
每個位元都有兩種可能 一種就是原本相同不用改變 一種就是不同
需要改成要隱藏訊息的位元,所以就在可變可不變之下最多差異是
2*2*2=8,最多情況就是到<=256色情況,所以可利用的顏色數大多
不如原先256色多,大多情形 在遷入隱藏訊息之後呈現的圖片,
才比較黯淡。
week1
第一篇資訊隱藏心得
上週講的影像格式跟壓縮方法都不是很了解,所以去網路上察看一些相關的資訊,希望這週更能融入聽懂老師教什麼,畢竟這門因該是我,第一次修多媒體學程的科目
真正去查了才知道有數十種以上格式,不然平常有應用到
的因該只有pics跟jpg格式,因為要把相片檔案縮小,跟
gif因常看到會動的圖檔都是此格式
現在一一列出這週看的檔案格式,觀看了解後的心得: bmp:懂了點陣圖的意思,跟電視上看到骨牌秀倒下呈現出
一副圖的道理一樣,像要做800*600,4bits的圖等於要48萬
個骨牌去排,而且規定只有16個索引顏色,顏色越多越逼
真,自然而然更需要更多bits數, 檔案野會越來越大,
共分24bits即為全彩(1677萬色)、16bits(65536色)、
8bits(256色)、4bits(16色)、1bits(單色),但這圖檔不能壓縮
Jpg: 幾乎所有數位相機都支援jpg記錄影像,也可支援24bits,
至於準確度跟壓縮比會成反比,想要較高的解析度就需要
比較低的壓縮比,自然而然也需要更多硬碟空間存放所以看
個人需求而去抉擇,利用數位餘弦轉換法(DCT)來壓縮,這
是會失真的壓縮格式,所以每次調整最好是自己另存新檔,
不然再重覆修改圖片下,可能精準度會越來越差
Gif:這壓縮方法是改良的藍波- 立夫- 衛曲法,以可變長度碼來編碼其索引值,可有效的節省壓縮後的空間,提高壓縮的比例
藍波- 立夫- 衛曲法又稱字串表(String Table) 壓縮法,基本的原理
是將原始影像資料中重複的字串編成一個表,然後再利用表上的
索引值來取代原始影像資料中的字串,由於索引值的體積遠比原始
影像中的字串體積來的小
這跟今天翻書跟一個最基本的壓縮原理很像L開頭的我沒記忘了….,比如一行字串是aaaaabbbbccccdddd假設需要17個單位去儲存,被壓縮成表示成 5個a 4個b 4個c 4個d,只需12個單位就儲存,大家還是明白本意,但儲放空間就少了30%,達到壓縮的效果,解壓縮時5就像是索引值,a就像是符號,就像是看到索引是5,就要印出a這個符號5次,就達到解壓縮的效果,也不失真,
所以我想gif格式為什麼不失真的原因就在這, 將重複字串編成一個表,之後在依索引值,知道這字串要放到哪個位置上去,所以就跟原本圖一樣不會失真了,而又是改良的可以改變長度碼,就不會受限於固定長度,造成小缺口不能放資料,造成不用浪費空間
至於下面那段話 它還具透明功能,只要指定色盤中的某種顏色為透明色即可,(例如:人在藍色布幕前拍照,將藍色設定為透明,就去掉藍色部分),適用於人或商品的影像去背處理 不太能怎能了解表達的意思,老師有看到在教一下,謝謝
下面這三個表格數據是從網路找到的,由256色影像壓縮結果可以看出,為什麼現在逛網頁常看到的圖檔,我想因該是因為壓縮效果最好而且還不失真,大大減少了檔案大小也加快開啟網頁的速度
而另外兩個數據則是看出有失真的壓縮率遠比無失真的壓縮率好,jpg在使用者幾乎無法察覺的失真情況下,jpg 的壓縮率可以達到5% ~15%,所以網路上的圖片格式常常都是jpg格式,對加快網路速度方面也有幫助


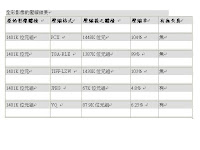
這是我參考的網址:
http://content.edu.tw/senior/life_tech/tc_t2/inform/ref/knowfile.htm
http://tw.knowledge.yahoo.com/question/?qid=1005020702402
http://www.cs.ccu.edu.tw/~ccc/article/image_compression.htm
上週講的影像格式跟壓縮方法都不是很了解,所以去網路上察看一些相關的資訊,希望這週更能融入聽懂老師教什麼,畢竟這門因該是我,第一次修多媒體學程的科目
真正去查了才知道有數十種以上格式,不然平常有應用到
的因該只有pics跟jpg格式,因為要把相片檔案縮小,跟
gif因常看到會動的圖檔都是此格式
現在一一列出這週看的檔案格式,觀看了解後的心得: bmp:懂了點陣圖的意思,跟電視上看到骨牌秀倒下呈現出
一副圖的道理一樣,像要做800*600,4bits的圖等於要48萬
個骨牌去排,而且規定只有16個索引顏色,顏色越多越逼
真,自然而然更需要更多bits數, 檔案野會越來越大,
共分24bits即為全彩(1677萬色)、16bits(65536色)、
8bits(256色)、4bits(16色)、1bits(單色),但這圖檔不能壓縮
Jpg: 幾乎所有數位相機都支援jpg記錄影像,也可支援24bits,
至於準確度跟壓縮比會成反比,想要較高的解析度就需要
比較低的壓縮比,自然而然也需要更多硬碟空間存放所以看
個人需求而去抉擇,利用數位餘弦轉換法(DCT)來壓縮,這
是會失真的壓縮格式,所以每次調整最好是自己另存新檔,
不然再重覆修改圖片下,可能精準度會越來越差
Gif:這壓縮方法是改良的藍波- 立夫- 衛曲法,以可變長度碼來編碼其索引值,可有效的節省壓縮後的空間,提高壓縮的比例
藍波- 立夫- 衛曲法又稱字串表(String Table) 壓縮法,基本的原理
是將原始影像資料中重複的字串編成一個表,然後再利用表上的
索引值來取代原始影像資料中的字串,由於索引值的體積遠比原始
影像中的字串體積來的小
這跟今天翻書跟一個最基本的壓縮原理很像L開頭的我沒記忘了….,比如一行字串是aaaaabbbbccccdddd假設需要17個單位去儲存,被壓縮成表示成 5個a 4個b 4個c 4個d,只需12個單位就儲存,大家還是明白本意,但儲放空間就少了30%,達到壓縮的效果,解壓縮時5就像是索引值,a就像是符號,就像是看到索引是5,就要印出a這個符號5次,就達到解壓縮的效果,也不失真,
所以我想gif格式為什麼不失真的原因就在這, 將重複字串編成一個表,之後在依索引值,知道這字串要放到哪個位置上去,所以就跟原本圖一樣不會失真了,而又是改良的可以改變長度碼,就不會受限於固定長度,造成小缺口不能放資料,造成不用浪費空間
至於下面那段話 它還具透明功能,只要指定色盤中的某種顏色為透明色即可,(例如:人在藍色布幕前拍照,將藍色設定為透明,就去掉藍色部分),適用於人或商品的影像去背處理 不太能怎能了解表達的意思,老師有看到在教一下,謝謝
下面這三個表格數據是從網路找到的,由256色影像壓縮結果可以看出,為什麼現在逛網頁常看到的圖檔,我想因該是因為壓縮效果最好而且還不失真,大大減少了檔案大小也加快開啟網頁的速度
而另外兩個數據則是看出有失真的壓縮率遠比無失真的壓縮率好,jpg在使用者幾乎無法察覺的失真情況下,jpg 的壓縮率可以達到5% ~15%,所以網路上的圖片格式常常都是jpg格式,對加快網路速度方面也有幫助
這是我參考的網址:
http://content.edu.tw/senior/life_tech/tc_t2/inform/ref/knowfile.htm
http://tw.knowledge.yahoo.com/question/?qid=1005020702402
http://www.cs.ccu.edu.tw/~ccc/article/image_compression.htm
2007年6月7日 星期四
Week 14 : 上課問題
首先看到這份資料,是網路上的資料,
之前就有看過維紀百科的東西,
中文的發現一大堆東西看不懂,後來比較偏愛英文
關於這份文件,剛看可能不太了解他再說什麼,
有很多的專有名詞,看不懂的比看的懂得多
文章第一段,我提出質疑
文:"PNG 可以被用來無失真地儲存照片,
但是檔案太大,不適合在網頁上放照片"
我記得 PNG,是 Portable Network Graphics
從字面上來推敲,應該是用於網路上的檔案格式
怎麼會說檔案太大,不適合放在網頁上?
之前有看稍微看一下 DCT 的東西,但是還是不了解為何要這樣做。
還有什麼是量化矩陣? 何謂頻率空間?
之前就有看過維紀百科的東西,
中文的發現一大堆東西看不懂,後來比較偏愛英文
關於這份文件,剛看可能不太了解他再說什麼,
有很多的專有名詞,看不懂的比看的懂得多
文章第一段,我提出質疑
文:"PNG 可以被用來無失真地儲存照片,
但是檔案太大,不適合在網頁上放照片"
我記得 PNG,是 Portable Network Graphics
從字面上來推敲,應該是用於網路上的檔案格式
怎麼會說檔案太大,不適合放在網頁上?
之前有看稍微看一下 DCT 的東西,但是還是不了解為何要這樣做。
還有什麼是量化矩陣? 何謂頻率空間?
JPEG檔案預讀...
看了之後...疑問有點多,
他所謂的YUV是類似RGB的意思嗎?
最不懂的地方是...DC係數?
以及Discrete cosine transform那裡,
到底為什麼矩陣最左上角的(絕對)值會最大呢?
是怎麼算的?
為什麼Image中的每個成份(y,u,v),
是用8 * 8的pixels區域?
色彩空間跟頻率空間?有啥關聯嗎?
他所謂的YUV是類似RGB的意思嗎?
最不懂的地方是...DC係數?
以及Discrete cosine transform那裡,
到底為什麼矩陣最左上角的(絕對)值會最大呢?
是怎麼算的?
為什麼Image中的每個成份(y,u,v),
是用8 * 8的pixels區域?
色彩空間跟頻率空間?有啥關聯嗎?
Week 14 - JPEG
JPEG的格式是壓縮的,利用人類的眼睛對於高頻率的事物比較不敏感,讓壓縮後的圖片看起來不會有奇怪的感覺。它可儲存的顏色也很多,最多16百萬色,幾乎所有的數位相機都支援JPEG的影像,它精準記錄每一個像素的亮度,並取出平均色調壓縮影像,並且用某一點顏色代表周圍附近的顏色
2007年6月6日 星期三
YCbCr與YUV傻傻分不清楚
由於上個禮拜沒來上課
所以本週主要是由已經有人po的文章來學習
本週要開始討論的主題是JPEG
從大家找來的文章中發現
有人在說YUV有人在講YCbCr
雖然從維基百科中得知
基本上兩個空間是可以替換使用地(why?)
所以我想概念上應該不會有太大的差別(really?)
就Y而言指的是亮度這點沒有問題
而Cb與Cr呢?
從原文來看是說一種紅色與藍色的色差值
(Cb and Cr are the blue and red chroma components)
U與V也是類似的意思
然而這兩者都是在指色差的意思並不好懂
我想用看圖的方式也許比較能理解那是什麼
如下圖
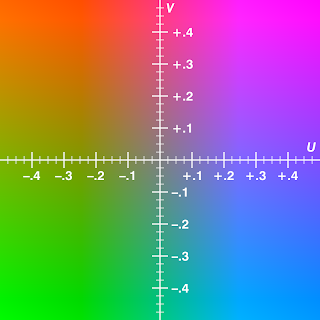
不過這兩者本質上還是不一樣的
此兩者常被誤會但其實是兩個完全不同的格式
一個是類比系統(analog system with scale factors)
另一個則是用數位系統(digital YCbCr system)
Reference:
YUV
YCbCr
所以本週主要是由已經有人po的文章來學習
本週要開始討論的主題是JPEG
從大家找來的文章中發現
有人在說YUV有人在講YCbCr
雖然從維基百科中得知
基本上兩個空間是可以替換使用地(why?)
所以我想概念上應該不會有太大的差別(really?)
就Y而言指的是亮度這點沒有問題
而Cb與Cr呢?
從原文來看是說一種紅色與藍色的色差值
(Cb and Cr are the blue and red chroma components)
U與V也是類似的意思
然而這兩者都是在指色差的意思並不好懂
我想用看圖的方式也許比較能理解那是什麼
如下圖

不過這兩者本質上還是不一樣的
此兩者常被誤會但其實是兩個完全不同的格式
一個是類比系統(analog system with scale factors)
另一個則是用數位系統(digital YCbCr system)
Reference:
YUV
YCbCr
Week 14: JPEG
雖然平常在網路上還滿常見到JPEG,
但我對他的印象始終停留在
1.一種影像格式(picture1.jpg)
2.使用失真壓縮(檔案比.bmp檔小很多,但是圖片會變醜)
3.相機的圖片直接使用jpg檔案
除此之外就不知道關於它的更多東西,剛好藉此來對他做個剖析
由於英文閱讀能力不佳
所以我選擇了維基百科繁體中文版做個閱讀
維基百科上說JPEG是採用把影像從RGB轉換成Y(像素亮度)U(色調)V(飽和度)
並說"比起色調與飽和度,人類的眼睛對於像素的亮度更加敏感"
並且把編碼器(encoder)建立在這個理論的基礎上
據說有用到量化...不過看到一堆數字就先眼花了@_@
看到那區時,稍微看了一下那堆數字與壓縮的相關性
似乎跟編碼解碼有關,但不是很能理解那些所謂的過程
後面有提到關於JPEG的用法(用途)跟GIF相較之下的優點(?)
"JPEG在色調及顏色平滑變化的相片或是寫實繪畫
(painting)上可以達到它最佳的效果。
在這種情況下,它通常比完全無失真方法作得更好,
仍然可以產生非常好看的影像(事實上它會比其他
一般的方法像是GIF產生更高品質的影像,
因為GIF對於線條繪畫(drawing)和圖示的圖形是無失真,
但針對全彩影像則需要極困難的量化)"
提到了線條繪圖,不禁讓我想起了一些以向量來做圖的軟體,
不知道向量圖是否也有圖片壓縮的困擾,是否也會用到JPEG之類的..
雖然這個聯想似乎怪怪的....囧
此外我試著把軟體畫出的bmp(彎彎的圖片)存成GIF與JPEG
用肉眼看的感覺,是GIF失真情況比較嚴重!
不知道該從何解釋起...(還是我又實驗錯誤??)
[以上是一點小心得跟看法]
這篇文章一不小心打到一半就送出了 囧
但我對他的印象始終停留在
1.一種影像格式(picture1.jpg)
2.使用失真壓縮(檔案比.bmp檔小很多,但是圖片會變醜)
3.相機的圖片直接使用jpg檔案
除此之外就不知道關於它的更多東西,剛好藉此來對他做個剖析
由於英文閱讀能力不佳
所以我選擇了維基百科繁體中文版做個閱讀
維基百科上說JPEG是採用把影像從RGB轉換成Y(像素亮度)U(色調)V(飽和度)
並說"比起色調與飽和度,人類的眼睛對於像素的亮度更加敏感"
並且把編碼器(encoder)建立在這個理論的基礎上
據說有用到量化...不過看到一堆數字就先眼花了@_@
看到那區時,稍微看了一下那堆數字與壓縮的相關性
似乎跟編碼解碼有關,但不是很能理解那些所謂的過程
後面有提到關於JPEG的用法(用途)跟GIF相較之下的優點(?)
"JPEG在色調及顏色平滑變化的相片或是寫實繪畫
(painting)上可以達到它最佳的效果。
在這種情況下,它通常比完全無失真方法作得更好,
仍然可以產生非常好看的影像(事實上它會比其他
一般的方法像是GIF產生更高品質的影像,
因為GIF對於線條繪畫(drawing)和圖示的圖形是無失真,
但針對全彩影像則需要極困難的量化)"
提到了線條繪圖,不禁讓我想起了一些以向量來做圖的軟體,
不知道向量圖是否也有圖片壓縮的困擾,是否也會用到JPEG之類的..
雖然這個聯想似乎怪怪的....囧
此外我試著把軟體畫出的bmp(彎彎的圖片)存成GIF與JPEG
用肉眼看的感覺,是GIF失真情況比較嚴重!
不知道該從何解釋起...(還是我又實驗錯誤??)
[以上是一點小心得跟看法]
這篇文章一不小心打到一半就送出了 囧
Week 14 PPT_version2
原本應該上週就要發表的
但因為畢業考給自己了一個理由
拖了一個禮拜
其實就是發懶了= =
修改的主要內容如下
1.更正投影片內容
2.條列式
3.動畫輔助
4.擷取出來關鍵字或句
連結如下:
Introduction_V2
但因為畢業考給自己了一個理由
拖了一個禮拜
其實就是發懶了= =
修改的主要內容如下
1.更正投影片內容
2.條列式
3.動畫輔助
4.擷取出來關鍵字或句
連結如下:
Introduction_V2
[week 14] JPEG
稍微整理了一下在維基百科上的JPEG資料
本來就大致上有點知道JPEG的壓縮方式,不過細讀了這個有更加清楚一些
運用在加密上,也許,可能要先把JPEG的資訊作一次解碼才把資訊藏進去,或許要想想別的作法,以下是整理的JPEG相關資料
JPEG是一種針對相片影像而廣泛使用的一種失真壓縮標準方法。使用這種壓縮的檔案格式一般也被稱為JPEG;在所有平臺上*.jpg是最普遍的。
這個名稱代表Joint Photographic Experts Group(聯合圖像專家小組)。
JPEG/JFIF是最普遍在全球資訊網(World Wide Web)上被用來儲存和傳輸照片的格式。它並不適合於線條繪圖(drawing)和其他文字或圖示(iconic)的圖形,因為它的壓縮方法用在這些圖形的型態上,會得到不適當的結果
首先,影像由RGB(紅綠藍)轉換為一種稱為YUV的不同色彩空間。
Y 成份表示一個像素的亮度
U 和 V 成份一起表示色調與飽和度。
接著減少 U 和 V 的成份(稱為"縮減取樣"或"色度抽樣"(chroma subsampling)。在JPEG上這種縮減取樣的比例可以是4:4:4(無縮減取樣),4:2:2(在水平方向 2 的倍數中取一個),以及最普遍的4:2:0(在水平和垂直方向 2 的倍數中取一個)。對於壓縮過程的剩餘部份,Y、U、和 V 都是以非常類似的方式來個別地處理。
下一步,影像中的每個成份(Y, U, V)每一個是以 8 乘以 8 的像素如磁磚般排列成為一個個的區域,每一區使用二維的離散餘弦變換(Discrete cosine transform)轉換到頻率空間。
最後作量化(Quantization)和處理失真比率情況
本來就大致上有點知道JPEG的壓縮方式,不過細讀了這個有更加清楚一些
運用在加密上,也許,可能要先把JPEG的資訊作一次解碼才把資訊藏進去,或許要想想別的作法,以下是整理的JPEG相關資料
JPEG是一種針對相片影像而廣泛使用的一種失真壓縮標準方法。使用這種壓縮的檔案格式一般也被稱為JPEG;在所有平臺上*.jpg是最普遍的。
這個名稱代表Joint Photographic Experts Group(聯合圖像專家小組)。
JPEG/JFIF是最普遍在全球資訊網(World Wide Web)上被用來儲存和傳輸照片的格式。它並不適合於線條繪圖(drawing)和其他文字或圖示(iconic)的圖形,因為它的壓縮方法用在這些圖形的型態上,會得到不適當的結果
首先,影像由RGB(紅綠藍)轉換為一種稱為YUV的不同色彩空間。
Y 成份表示一個像素的亮度
U 和 V 成份一起表示色調與飽和度。
接著減少 U 和 V 的成份(稱為"縮減取樣"或"色度抽樣"(chroma subsampling)。在JPEG上這種縮減取樣的比例可以是4:4:4(無縮減取樣),4:2:2(在水平方向 2 的倍數中取一個),以及最普遍的4:2:0(在水平和垂直方向 2 的倍數中取一個)。對於壓縮過程的剩餘部份,Y、U、和 V 都是以非常類似的方式來個別地處理。
下一步,影像中的每個成份(Y, U, V)每一個是以 8 乘以 8 的像素如磁磚般排列成為一個個的區域,每一區使用二維的離散餘弦變換(Discrete cosine transform)轉換到頻率空間。
最後作量化(Quantization)和處理失真比率情況
[week14]JPEG小簡介
各位鄉親阿
我又來啦咧了
沒錯!!
如同老師所預告的
我們在這個禮拜要進入 Information Hiding in JPEG的部份了
既然要談到在JPEG中藏資訊的方法
怎麼可以不知道JPEG是怎麼做的呢...
----以下所說的話 僅代表正cos一個人的立場 有錯的話...那也是正常的...反正我是學生嘛XDD----
1.JPEG是一種針對相片影像而廣泛使用的一種失真壓縮標準方法。
我們之前談的影像檔呢
都是以RGB的方式來紀錄color值的
可是JPEG這傢伙呢 卻是以YCbCr的方式來紀錄的喔
根據我從維基百科抄下來的話
RGB方式將所有的顏色資訊作同等的處理,雖然有最高的畫質,但由於RGB方式對傳輸頻寬
和儲存空間的消耗太大,為節省頻寬,使用色差方式來傳送與紀錄分量視訊是現在的主流。
色差在設計上利用了「人眼對明度較敏感,而對彩度較不敏感」的特性,
將視訊中的色彩資訊加以削減,轉換公式如下:
明度: Y = 0.299*R + 0.587*G + 0.114*B
色差: Cb= 0.564*(B-Y) = -0.169*R - 0.331*G + 0.500*B
Cr= 0.713*(R-Y) = 0.500*R - 0.419*G - 0.081*B
所謂的「色差」即為顏色值與明度之間的差值。轉換過後的顏色資訊量被刪減了約一半,
但由於人眼的特性,使得色差處理過後的影像與原始影像的差異很難被察覺。
最終的色差資料與RGB資料相比節省了1/3的頻寬。
嘖...
我之前都覺得YCbCr和RGB一樣...
不過就是座標軸轉換而已嘛...
為什麼它會說節省頻寬咧...
到底是哪裏被減掉啦...
反正他換成YCbCr之後阿...
因為人眼對這三個座標軸的強度感受不同阿
就可以分開壓比較多或比較少...
在Down Sampling那邊...
四個取一個跟 兩個取一個 取出來的量就不同啦...
2.8x8的陣列做處理
我不知道為什麼是8x8...
他高興吧...
3.DCT轉換
從空間域轉到頻率域...
同上...我不知道為什麼...
維基百科有關DCT的連結在這...
可是我知道DCT轉換這邊沒有失真...
4.量化
我不會解釋這邊...
可是這邊的目的也是降低資料的複雜度啦...以後比較好壓縮...
我只會舉例
像是16.1 16.2 16.3 16.5 16.8 16.75 16.9 17.1 16.2 17.25 17.33 17.54 這樣子的數列
如果都取整數值作代表的話
就會變成 16 16 16 16 16 16 16 16 17 16 17 16 17 17 17
我們可以記成 16*5 + 17*1 + 16*1 + 17*3
這樣傳輸的資料量就變少啦...
5.zig-zag
把那個8x8的陣列變成一維陣列
6.huffmancoding
我想睡覺了啦...
寫blog超累的...
我有寫了一個JPEG Decoder 的半成品...
大家有空可以玩一下...
我下次再補其他的部份好了...
我又來啦咧了
沒錯!!
如同老師所預告的
我們在這個禮拜要進入 Information Hiding in JPEG的部份了
既然要談到在JPEG中藏資訊的方法
怎麼可以不知道JPEG是怎麼做的呢...
----以下所說的話 僅代表正cos一個人的立場 有錯的話...那也是正常的...反正我是學生嘛XDD----
1.JPEG是一種針對相片影像而廣泛使用的一種失真壓縮標準方法。
我們之前談的影像檔呢
都是以RGB的方式來紀錄color值的
可是JPEG這傢伙呢 卻是以YCbCr的方式來紀錄的喔
根據我從維基百科抄下來的話
RGB方式將所有的顏色資訊作同等的處理,雖然有最高的畫質,但由於RGB方式對傳輸頻寬
和儲存空間的消耗太大,為節省頻寬,使用色差方式來傳送與紀錄分量視訊是現在的主流。
色差在設計上利用了「人眼對明度較敏感,而對彩度較不敏感」的特性,
將視訊中的色彩資訊加以削減,轉換公式如下:
明度: Y = 0.299*R + 0.587*G + 0.114*B
色差: Cb= 0.564*(B-Y) = -0.169*R - 0.331*G + 0.500*B
Cr= 0.713*(R-Y) = 0.500*R - 0.419*G - 0.081*B
所謂的「色差」即為顏色值與明度之間的差值。轉換過後的顏色資訊量被刪減了約一半,
但由於人眼的特性,使得色差處理過後的影像與原始影像的差異很難被察覺。
最終的色差資料與RGB資料相比節省了1/3的頻寬。
嘖...
我之前都覺得YCbCr和RGB一樣...
不過就是座標軸轉換而已嘛...
為什麼它會說節省頻寬咧...
到底是哪裏被減掉啦...
反正他換成YCbCr之後阿...
因為人眼對這三個座標軸的強度感受不同阿
就可以分開壓比較多或比較少...
在Down Sampling那邊...
四個取一個跟 兩個取一個 取出來的量就不同啦...
2.8x8的陣列做處理
我不知道為什麼是8x8...
他高興吧...
3.DCT轉換
從空間域轉到頻率域...
同上...我不知道為什麼...
維基百科有關DCT的連結在這...
可是我知道DCT轉換這邊沒有失真...
4.量化
我不會解釋這邊...
可是這邊的目的也是降低資料的複雜度啦...以後比較好壓縮...
我只會舉例
像是16.1 16.2 16.3 16.5 16.8 16.75 16.9 17.1 16.2 17.25 17.33 17.54 這樣子的數列
如果都取整數值作代表的話
就會變成 16 16 16 16 16 16 16 16 17 16 17 16 17 17 17
我們可以記成 16*5 + 17*1 + 16*1 + 17*3
這樣傳輸的資料量就變少啦...
5.zig-zag
把那個8x8的陣列變成一維陣列
6.huffmancoding
我想睡覺了啦...
寫blog超累的...
我有寫了一個JPEG Decoder 的半成品...
大家有空可以玩一下...
我下次再補其他的部份好了...
2007年6月4日 星期一
JPEG是甚麼?
簡而言之,
JPG / JPEG 所使用的『主要』是破壞性( 失真 )的壓縮方式,它可以針對彩色或灰階的影像進行大幅度的壓縮。是由Joint Photographic Experts Group(聯合圖像專家小組)的縮寫而來的,利用
人類的眼睛對高頻的部份較不敏感,來大量壓縮FILE的大小,JPEG也被用在各個領域上,缺點是會造成失真,但即使如此, JPEG 還是被廣泛的使用。
參考網站:
http://zh.wikipedia.org/wiki/JPEG
http://www.dcview.com.tw/photoclass/file_fmt/jpeg_1.htm
JPG / JPEG 所使用的『主要』是破壞性( 失真 )的壓縮方式,它可以針對彩色或灰階的影像進行大幅度的壓縮。是由Joint Photographic Experts Group(聯合圖像專家小組)的縮寫而來的,利用
人類的眼睛對高頻的部份較不敏感,來大量壓縮FILE的大小,JPEG也被用在各個領域上,缺點是會造成失真,但即使如此, JPEG 還是被廣泛的使用。
參考網站:
http://zh.wikipedia.org/wiki/JPEG
http://www.dcview.com.tw/photoclass/file_fmt/jpeg_1.htm
2007年5月31日 星期四
Introduction-2
http://ss24.mcu.edu.tw/~s3360265/Introduction-2.ppt
投影片修改
封面有加上論文名稱、作者
放上一些圖片
我的第一個投影片字太多,感覺比較沒有重點
這一次我把重點標出來,有比較條列式的感覺
投影片修改
封面有加上論文名稱、作者
放上一些圖片
我的第一個投影片字太多,感覺比較沒有重點
這一次我把重點標出來,有比較條列式的感覺
PPT修改
修改部分如下:
1. 投影片封面加入作者與報告人姓名
2. 減少贅字
3. 將EZ Stego過程改成動畫
4. 投影片編號
投影片如下:
http://ftp.csie.mcu.edu.tw/~s2361164/paper_2_2.ptt
1. 投影片封面加入作者與報告人姓名
2. 減少贅字
3. 將EZ Stego過程改成動畫
4. 投影片編號
投影片如下:
http://ftp.csie.mcu.edu.tw/~s2361164/paper_2_2.ptt
2007年5月26日 星期六
2007年5月24日 星期四
Paper投影片
這次paper是英文的,莫名奇妙投影片也跟著用英文做,是我第一次用英文做投影片。再加上paper許多地方我看不懂,所以我覺得投影片做的很不好。
http://ss24.mcu.edu.tw/~s2361164/paper_2.ppt
http://ss24.mcu.edu.tw/~s2361164/paper_2.ppt
2007年5月17日 星期四
Paper問題自我解答
上次上課,老師只講了摘要,就等於把整篇Paper講完,讓我有點吃驚!上次不懂的地方也了解了,所以現在可以回答自己提出的問題。
Jiri Fridrich的方法如下:
1. 欲隱藏的資料大小M bits,餵key給PRNG(Pseudo-random genertor),取得M個pixel來藏。
2. 計算調色盤中每個顏色的相似色,計算方式是兩個pixel的RGB值,個別相減再平方,三個平方結果相加,最後開根號,結果愈小,兩個顏色愈相似。
3. 若欲隱藏的第一個位元為1,將第一個位子的RGB相加後mod2,得到parity值,若parity值為1,便直接藏入,若parity為0,則找第一個位子的下一個相似顏色的parity,直到找到可藏的顏色為止。
4. 找到可藏的顏色後,便將原本的顏色取代掉,隱藏動作完成。
優點:
每次取代的顏色,一定會是與原本相似的顏色,不會像EZ Stego,取代的顏色可能是與原本的顏色完全不相近,降低失真的程度。
對於第3步,有點不確定,歡迎大家發表意見,討論討論。
Jiri Fridrich的方法如下:
1. 欲隱藏的資料大小M bits,餵key給PRNG(Pseudo-random genertor),取得M個pixel來藏。
2. 計算調色盤中每個顏色的相似色,計算方式是兩個pixel的RGB值,個別相減再平方,三個平方結果相加,最後開根號,結果愈小,兩個顏色愈相似。
3. 若欲隱藏的第一個位元為1,將第一個位子的RGB相加後mod2,得到parity值,若parity值為1,便直接藏入,若parity為0,則找第一個位子的下一個相似顏色的parity,直到找到可藏的顏色為止。
4. 找到可藏的顏色後,便將原本的顏色取代掉,隱藏動作完成。
優點:
每次取代的顏色,一定會是與原本相似的顏色,不會像EZ Stego,取代的顏色可能是與原本的顏色完全不相近,降低失真的程度。
對於第3步,有點不確定,歡迎大家發表意見,討論討論。
Paper閱讀心得
本週課程主題是討論 J. Fridrich 論文 A New Steganographic Method for Palette Images 的核心觀念!
我也根據此新的技術是這去寫寫看程式!!!
首先我先將圖片的調色盤找出來==>

接著我自己規定我要Random的Seed,也就是之後要解出我所隱藏的資訊的Key!!
而我所隱藏的是八個bit 1111 1100 !!!!

如果你輸入的密碼也就是我規定的Seed是錯誤的!!!
會顯示你輸入的密碼是錯誤的!!!並且按解出資訊也無法解出任何東西!!!

如果輸入的密碼是我所規定的 "1905",就可以看到我所隱藏的資訊 1111 1100這八個bit!!!

我也根據此新的技術是這去寫寫看程式!!!
首先我先將圖片的調色盤找出來==>

接著我自己規定我要Random的Seed,也就是之後要解出我所隱藏的資訊的Key!!
而我所隱藏的是八個bit 1111 1100 !!!!

如果你輸入的密碼也就是我規定的Seed是錯誤的!!!
會顯示你輸入的密碼是錯誤的!!!並且按解出資訊也無法解出任何東西!!!

如果輸入的密碼是我所規定的 "1905",就可以看到我所隱藏的資訊 1111 1100這八個bit!!!

2007年5月16日 星期三
Paper閱讀心得
問題:
其實我最大的問題應該就是在於...不知道自己的問題在哪裡!!(眾人毆)
應該是說,一直都在一種似懂非懂的感覺,說不出問題在哪裡...可是就是心存疑惑(認真貌)。
心得:
其實一開始看paper時,一直看到第三頁都隱約覺得內容似乎是老師上課時就提過的內容,所以也就沒有看的很仔細....用英文來說應該就是Scan過去吧(?)
後來老師在課堂上討論Abstract時,還是覺得哪個點卡住了,直到老師在學長的詢問下,使用白板解釋我才真正了解(R+G+B)%2=parity這件事情的意義。
筆記:找parity是否和藏的資料(0 or 1)相同,若不是則找parity一樣的相近顏色。
:paper中另一個公式 根號(R1-R2)^2+(G1-G2)^2+(B1-B2)^2則是為了找相近顏色
:所以步驟上是...1.先找到相近顏色,2看parity.若parity不相等,找次個相近顏色..以此類推。
其實我最大的問題應該就是在於...不知道自己的問題在哪裡!!(眾人毆)
應該是說,一直都在一種似懂非懂的感覺,說不出問題在哪裡...可是就是心存疑惑(認真貌)。
心得:
其實一開始看paper時,一直看到第三頁都隱約覺得內容似乎是老師上課時就提過的內容,所以也就沒有看的很仔細....用英文來說應該就是Scan過去吧(?)
後來老師在課堂上討論Abstract時,還是覺得哪個點卡住了,直到老師在學長的詢問下,使用白板解釋我才真正了解(R+G+B)%2=parity這件事情的意義。
筆記:找parity是否和藏的資料(0 or 1)相同,若不是則找parity一樣的相近顏色。
:paper中另一個公式 根號(R1-R2)^2+(G1-G2)^2+(B1-B2)^2則是為了找相近顏色
:所以步驟上是...1.先找到相近顏色,2看parity.若parity不相等,找次個相近顏色..以此類推。
2007年5月10日 星期四
Wee9 paper心得
問題一
在文章中提到了The parity bit of a color is defined as (R+G+B mod 2)
我想它的意思是指相似的顏色判定的方法是由R+G+B mod 2 的餘數來判斷
為何可以用這樣的方法來判定相似的顏色呢?
問題二
何謂PRNG呢?
只知道他的意思是指pseudo-random number generator
一種可以偽亂數產生器的方法
問題三
計算distance的方式
是用兩個pixel之間R,G,B的相減平方開根號來判斷
那如果要用來排序的話要怎麼決定比較的基準點呢?
找最暗的嘛?可如果有相同的亮度的質那要怎麼決定用哪個為基準點呢?
因為相同的亮度是有可能會是兩種不同的顏色
在文章中提到了The parity bit of a color is defined as (R+G+B mod 2)
我想它的意思是指相似的顏色判定的方法是由R+G+B mod 2 的餘數來判斷
為何可以用這樣的方法來判定相似的顏色呢?
問題二
何謂PRNG呢?
只知道他的意思是指pseudo-random number generator
一種可以偽亂數產生器的方法
問題三
計算distance的方式
是用兩個pixel之間R,G,B的相減平方開根號來判斷
那如果要用來排序的話要怎麼決定比較的基準點呢?
找最暗的嘛?可如果有相同的亮度的質那要怎麼決定用哪個為基準點呢?
因為相同的亮度是有可能會是兩種不同的顏色
閱讀Paper後的心得與問題
Jiri Fridrich的方法與EZ Stego,兩者在調色盤的排序方式不同。Jiri Fridrich是依各個顏色之間的差距做排序,所以排序後,相鄰的兩個顏色會是相近的。而EZ Stego是依亮度(luminance)做排序,會造成部份相鄰顏色是不相近的。所以Jiri Fridrich的方法可降低更多的失真。
下面我簡單的做了一個小測試,先挑選幾個顏色(我挑的有點少),四個顏色分別為(0,0,0)、(57,42,42)、(88,143,82)和(82,102,143)。第1個是Jiri Fridrich的方法,先以第一個(0,0,0)做基準,算出與其他三色的差距,經過計算,第二個顏色為(57,42,42),再計算後兩個顏色與(57,42,42)的差距,選出第三個,以次類推。第2個是用亮度作排序,使用(R+G+B)/3後的結果做排序。第3個也是依亮度,但是使用R*0.299+G*0.587+B*0.114後的結果做排序。結果如下圖,相信多選些顏色可看出更明顯的差距。
 不過我對於之後的隱藏資料的動作不是很了解,是......與我們同學寫的改index的方法類似嗎?純粹在調色盤的排序方式而已。
不過我對於之後的隱藏資料的動作不是很了解,是......與我們同學寫的改index的方法類似嗎?純粹在調色盤的排序方式而已。
下面我簡單的做了一個小測試,先挑選幾個顏色(我挑的有點少),四個顏色分別為(0,0,0)、(57,42,42)、(88,143,82)和(82,102,143)。第1個是Jiri Fridrich的方法,先以第一個(0,0,0)做基準,算出與其他三色的差距,經過計算,第二個顏色為(57,42,42),再計算後兩個顏色與(57,42,42)的差距,選出第三個,以次類推。第2個是用亮度作排序,使用(R+G+B)/3後的結果做排序。第3個也是依亮度,但是使用R*0.299+G*0.587+B*0.114後的結果做排序。結果如下圖,相信多選些顏色可看出更明顯的差距。
 不過我對於之後的隱藏資料的動作不是很了解,是......與我們同學寫的改index的方法類似嗎?純粹在調色盤的排序方式而已。
不過我對於之後的隱藏資料的動作不是很了解,是......與我們同學寫的改index的方法類似嗎?純粹在調色盤的排序方式而已。
Week9 - J. Fridrich's Method
1)最通用的顏色篩選基準 - error diffusion,不太懂怎麼做的(可能是不太懂be rounded to的意思),為什麼這樣做?
2)J. Fridrich's Method,為什麼the parity of color(R+B+G mod 2)與要藏的bit相同的情況下,取得的顏色會比之前我們用的方法找的顏色更好?(已知之前方法找的顏色會有斷層)
<註>
1.以上問題的前提是在我沒有誤解英文的情況下。
2.因為有點混,所以論文是跳著看的,可能會少看什麼重點,請無視不該問的問題。
3.問題還有,在還未確定不是英文障礙前,暫不提出。
2)J. Fridrich's Method,為什麼the parity of color(R+B+G mod 2)與要藏的bit相同的情況下,取得的顏色會比之前我們用的方法找的顏色更好?(已知之前方法找的顏色會有斷層)
<註>
1.以上問題的前提是在我沒有誤解英文的情況下。
2.因為有點混,所以論文是跳著看的,可能會少看什麼重點,請無視不該問的問題。
3.問題還有,在還未確定不是英文障礙前,暫不提出。
閱讀paper心得
閱讀問題:
The two most frequently used are based on iterative dividing of the three-dimensional color cube into two boxes with approximately the same number of colors.
我不太懂這句的意思,反覆的切割一個三維的立體用接近相同數字的顏色到兩個box試什麼意思啊!!!!
user-defined seed
這個由使用者決定的因素是什麼???是不是兩個pixel 的RGB相差平方開根號的值.是由我們
自己決定的.
R+G+B/2
這個算出相似的顏色.跟0.299*r + 0.587*g + 0.114 * b.有差不多嗎??如果有差!!!哪個比較好.
閱讀心得:
這篇論文所說的EZ Stego 其實就是我們這幾個禮拜所寫的程式.
由調色盤所組成的圖片.要藏資訊都要先經過 1.降色 2.將調色盤排序
The two most frequently used are based on iterative dividing of the three-dimensional color cube into two boxes with approximately the same number of colors.
我不太懂這句的意思,反覆的切割一個三維的立體用接近相同數字的顏色到兩個box試什麼意思啊!!!!
user-defined seed
這個由使用者決定的因素是什麼???是不是兩個pixel 的RGB相差平方開根號的值.是由我們
自己決定的.
R+G+B/2
這個算出相似的顏色.跟0.299*r + 0.587*g + 0.114 * b.有差不多嗎??如果有差!!!哪個比較好.
閱讀心得:
這篇論文所說的EZ Stego 其實就是我們這幾個禮拜所寫的程式.
由調色盤所組成的圖片.要藏資訊都要先經過 1.降色 2.將調色盤排序
2007年5月9日 星期三
心得
心得
他们研發了一種關於將資訊嵌入圖中的技術,他是以一種亂數的方式去產生一種亂數碼,它會改變原本顏色的值,最大可能被改變4到5次,這種技術可以更安全的資訊隱藏。
根據她的介紹,GIF檔轉成JPEG檔會一些資訊或格式上的破壞,為了改善這些缺點,我们便使用一些技術,如palette-based images 技術,它有幾個特性:在優點上:它易被設計,如:CCD。而在缺點部份:它的bit 大小是被限制的。
它提供2種方式:一是:vector quantization,另一個是 color quantization,它是利用人類的視覺系統以一種演算法來做顏色的調整和轉換。
在principles of steganographic methods 裡,優點在於:因為它隱藏資料後,比較看不出來有被改變,所以它比較安全。而缺點在:跟其它方法比較起來是被限制的。但是這個方法是有被改善的,他们企圖在palette裡面嵌入單一位元,很明顯的,這樣的方式,是可改善被限制住的這個缺點。
它有幾個步驟:1.先找到一個pixel’s RGB color, 2.從二位元的訊息中得到一個bit,並且取代索引的LSB。3.找一個新RGB color 4.在原本的palette裡,找一個新的RGB 的索引值,5.改便新RGB的pixel。這樣子的方式可避免顏色有太大的變化。
現在有個新的steganographic演算法,((R1-R2)^2+(G1-G2)^2+(B1-B2)^2)^1/2每個Pixel是用相近的顏色來加以計算。然後藉由這個計算的方式去找尋下一個最接近的顏色,直到找到我们要的目標顏色為止。這樣的方式是很容易被電腦所讀取的,因為它有一種規律在。但它仍然有訊息長度的限制。
總之,它是把每一個訊息藏在每一個pixel 裡,這種方式是比較安全的,不易被改變的。
他们研發了一種關於將資訊嵌入圖中的技術,他是以一種亂數的方式去產生一種亂數碼,它會改變原本顏色的值,最大可能被改變4到5次,這種技術可以更安全的資訊隱藏。
根據她的介紹,GIF檔轉成JPEG檔會一些資訊或格式上的破壞,為了改善這些缺點,我们便使用一些技術,如palette-based images 技術,它有幾個特性:在優點上:它易被設計,如:CCD。而在缺點部份:它的bit 大小是被限制的。
它提供2種方式:一是:vector quantization,另一個是 color quantization,它是利用人類的視覺系統以一種演算法來做顏色的調整和轉換。
在principles of steganographic methods 裡,優點在於:因為它隱藏資料後,比較看不出來有被改變,所以它比較安全。而缺點在:跟其它方法比較起來是被限制的。但是這個方法是有被改善的,他们企圖在palette裡面嵌入單一位元,很明顯的,這樣的方式,是可改善被限制住的這個缺點。
它有幾個步驟:1.先找到一個pixel’s RGB color, 2.從二位元的訊息中得到一個bit,並且取代索引的LSB。3.找一個新RGB color 4.在原本的palette裡,找一個新的RGB 的索引值,5.改便新RGB的pixel。這樣子的方式可避免顏色有太大的變化。
現在有個新的steganographic演算法,((R1-R2)^2+(G1-G2)^2+(B1-B2)^2)^1/2每個Pixel是用相近的顏色來加以計算。然後藉由這個計算的方式去找尋下一個最接近的顏色,直到找到我们要的目標顏色為止。這樣的方式是很容易被電腦所讀取的,因為它有一種規律在。但它仍然有訊息長度的限制。
總之,它是把每一個訊息藏在每一個pixel 裡,這種方式是比較安全的,不易被改變的。
閱讀paper後...的想法心得及問題
首先關於一些類似的專有名詞:
小弟不是很懂希望各位大大可以幫忙解析:
1.noise properties指的是哪些性質阿?
2.integrating properties又是指哪些性質
3.error diffusion 雖然段落中有一段提到,但是卻不是很懂,
4.noise model又是什麼東西?
5.其中提到"The redundancy of the data helps to conceal the presence of secret message."究竟資料的冗位是怎樣幫助隱藏呢?
paper最後有提到如何減低雜訊的技巧,有點fuzzy的觀點將選擇嵌入的pixel分權數0-1,但是問題是如果全部的pixel不巧的權數都不重,也就是說近0值的表示不適合選擇嵌入,若是不幸的大多數的pixel都不適合嵌入,那該怎樣去降低雜訊呢?而且用加權重的方式或許是很睿智的想法,但是相對的遷入後不容易被發現的的那先點畢竟是比較有限的,所以message的長度也會被限制阿!
小弟不是很懂希望各位大大可以幫忙解析:
1.noise properties指的是哪些性質阿?
2.integrating properties又是指哪些性質
3.error diffusion 雖然段落中有一段提到,但是卻不是很懂,
4.noise model又是什麼東西?
5.其中提到"The redundancy of the data helps to conceal the presence of secret message."究竟資料的冗位是怎樣幫助隱藏呢?
paper最後有提到如何減低雜訊的技巧,有點fuzzy的觀點將選擇嵌入的pixel分權數0-1,但是問題是如果全部的pixel不巧的權數都不重,也就是說近0值的表示不適合選擇嵌入,若是不幸的大多數的pixel都不適合嵌入,那該怎樣去降低雜訊呢?而且用加權重的方式或許是很睿智的想法,但是相對的遷入後不容易被發現的的那先點畢竟是比較有限的,所以message的長度也會被限制阿!
關於new steganographic
1. 將資訊藏在palette中
優:較好設計一個安全的方案
(不懂裡頭寫的noise properties是什麼意思,
讓我不懂他設計的方案,是關於嵌入資訊?
或是查詢是否有資訊?的方案,
也不懂後面為何會有a scanner, a CCD camera,...
那些東西是要做什麼的?能做什麼?
順帶一提,前面Eve為何要使用那些器材做影像的統計呢?
每個器材要查的是什麼東呢?
...如果跟題目沒關...可以跳過這個問題...)
缺:能藏資訊的容量較少
(最大只能藏到調色盤的容量)
2. 將資訊藏在image data中
優:能藏資訊的容量較多
缺:較難設計一個安全的方案
其他:
我steganography using palette-based images那大段,
他的四、五、六段意思都有點模糊。
其他都普普,可以大略(模糊的...)看懂意思。
優:較好設計一個安全的方案
(不懂裡頭寫的noise properties是什麼意思,
讓我不懂他設計的方案,是關於嵌入資訊?
或是查詢是否有資訊?的方案,
也不懂後面為何會有a scanner, a CCD camera,...
那些東西是要做什麼的?能做什麼?
順帶一提,前面Eve為何要使用那些器材做影像的統計呢?
每個器材要查的是什麼東呢?
...如果跟題目沒關...可以跳過這個問題...)
缺:能藏資訊的容量較少
(最大只能藏到調色盤的容量)
2. 將資訊藏在image data中
優:能藏資訊的容量較多
缺:較難設計一個安全的方案
其他:
我steganography using palette-based images那大段,
他的四、五、六段意思都有點模糊。
其他都普普,可以大略(模糊的...)看懂意思。
2007年4月26日 星期四
計算RMSE(Root Mean Square Error)
上週老師在上課最後提到MSE和PSNR,這兩個都是用來檢測兩張圖是否相似。
MSE的公式為:

PSNR的公式為:

MSE的值愈小,表示兩張圖愈相近。PSNR的愈大,表示兩張圖愈相近。
我試著寫了一個計算MSE和PSNR的小程式,計算方式是先分別將同座標的RGB值相減,
接著將相減後的值平方,累積所有平方後的值,最後累積值除以pixel數便是MSE。
片斷程式碼如下:
r = (point1[x*3+2]-point2[x*3+2])*(point1[x*3+2]-point2[x*3+2]);
g = (point1[x*3+1]-point2[x*3+1])*(point1[x*3+1]-point2[x*3+1]);
b = (point1[x*3]-point2[x*3])*(point1[x*3]-point2[x*3]);
sum = sum+r+g+b;
mse = sum/Hight*Width;
我不太確定這樣計算是否正確,希望其他人可以發表自己查到的結果,供大家討論。
程式執行圖片如下:
MSE的公式為:

PSNR的公式為:

MSE的值愈小,表示兩張圖愈相近。PSNR的愈大,表示兩張圖愈相近。
我試著寫了一個計算MSE和PSNR的小程式,計算方式是先分別將同座標的RGB值相減,
接著將相減後的值平方,累積所有平方後的值,最後累積值除以pixel數便是MSE。
片斷程式碼如下:
r = (point1[x*3+2]-point2[x*3+2])*(point1[x*3+2]-point2[x*3+2]);
g = (point1[x*3+1]-point2[x*3+1])*(point1[x*3+1]-point2[x*3+1]);
b = (point1[x*3]-point2[x*3])*(point1[x*3]-point2[x*3]);
sum = sum+r+g+b;
mse = sum/Hight*Width;
我不太確定這樣計算是否正確,希望其他人可以發表自己查到的結果,供大家討論。
程式執行圖片如下:






身體狀況不太好
所以好幾週沒去上課了
最近希望能慢慢把進度追上
不過看來只能夠慢慢來了
暫時先慢慢看老師寫的教學日誌來補
可能需要花點時間吧
雖然有點久了,不過上次寫的那個s-tools的檢查工具之前才看到學長說想try看看
那我現在補上,雖然知道有點晚了
http://www.csie.mcu.edu.tw/~s3360256/IH.rar
至於最近在弄的程式,我看先慢慢把進度給追上在說,應該還是來得及
這禮拜只能這樣交代一下了
所以好幾週沒去上課了
最近希望能慢慢把進度追上
不過看來只能夠慢慢來了
暫時先慢慢看老師寫的教學日誌來補
可能需要花點時間吧
雖然有點久了,不過上次寫的那個s-tools的檢查工具之前才看到學長說想try看看
那我現在補上,雖然知道有點晚了
http://www.csie.mcu.edu.tw/~s3360256/IH.rar
至於最近在弄的程式,我看先慢慢把進度給追上在說,應該還是來得及
這禮拜只能這樣交代一下了
2007年4月25日 星期三
S-Tool的發現
嗯 感覺這門課很深奧 有種不簡單的感覺 哈
因為基礎不夠深 所以我現階段努力摸索著S-Tool
並且了解圖檔的基本相關資訊等等 如果我自認為有重大發現
而大家覺得沒什麼時......請別笑我 >"< 哈 謝謝 以下就是我所謂測試的重大發現 哈 :p
 800*600 115KB
800*600 115KB
 800*600 129KB
800*600 129KB
檔名01 使用小畫家轉檔成GIF,檔案大小變成129KB。




可將其隱藏成功!


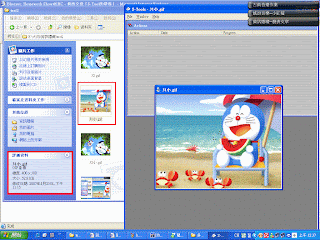

因為基礎不夠深 所以我現階段努力摸索著S-Tool
並且了解圖檔的基本相關資訊等等 如果我自認為有重大發現
而大家覺得沒什麼時......請別笑我 >"< 哈 謝謝 以下就是我所謂測試的重大發現 哈 :p
單看一個圖檔的大小其實是不能判定S-Tool可以將其隱藏滴~ 這該怎說呢?
以下是我的測試:
原始檔資訊:
圖1. JPG 檔
 800*600 115KB
800*600 115KB圖2. JPG 檔
 800*600 129KB
800*600 129KB檔名01 使用小畫家轉檔成GIF,檔案大小變成129KB。

檔名02. 使用小畫家轉檔成GIF,檔案大小變成140KB。

可將其隱藏成功!
Memory usage:481,064 bytes

檔名12 使用Photoimpact轉檔成GIF,最佳化128,檔案大小變成146KB。

檔名22 使用Photoimpact轉檔成GIF,最佳化128,檔案大小變成157KB。

可將其隱藏成功!
Memory usage:481,064 bytes

檔名31 使用Photoimpact轉檔成GIF,最佳化256,檔案大小變成184KB。

檔名32 使用Photoimpact轉檔成GIF,最佳化256,檔案大小變成203KB。

↑ 208,741 bytes is too much to fit in here, sorry.
無法隱藏成功!
檔名31小 使用Photoimpact轉檔成GIF,最佳化256,將檔案縮小為400*300,檔案大小變成52.8KB。

檔名32小 使用Photoimpact轉檔成GIF,最佳化256,將檔案縮小為400*300,檔案大小變成57.8KB。

↑ 59,230 bytes is too much to fit in here, sorry.
無法隱藏成功!
結論:
檔案大小並不是影響S-Tool可否隱藏資訊,圖形最佳化是主要影響來源。
◎ 最佳化256,圖檔是400*300,檔案大小是52.8KB,跟最佳化128,圖檔800*600,檔案是146KB,用到的記憶體誰大?
和同學的討論:
開啟時所吃的記憶體是圖越大就越大...400x300大小的全彩圖就是吃400x300x32bit的ram
存在硬碟裡的話,要看壓縮方法...
因為不知道最佳化256跟最佳化128的壓縮比例...所以不知道
但是用相同的壓縮方法的話...一定是圖越大越吃空間
※ 呼呼~ 以上就是我的結論與觀點
{kind=link}
Week8:灰階度排序後藏匿的圖
發燒了兩天,今天開始延續上禮拜的動作!
雖然上週回家就完成灰階度的排序!不過這次又再做了另一個小test不過應該是方法用錯吧!
先談談上次用的方法:
也就是灰階的方式排序後的調色盤:

以下是沒排序隱藏資訊的圖:

排序後隱藏資訊的圖:

最後則是謬論做的圖:

本想做成分群的效果,或許理論上可以讓加密的圖更清楚
雖然上週回家就完成灰階度的排序!不過這次又再做了另一個小test不過應該是方法用錯吧!
先談談上次用的方法:
也就是灰階的方式排序後的調色盤:

以下是沒排序隱藏資訊的圖:

排序後隱藏資訊的圖:

最後則是謬論做的圖:

本想做成分群的效果,或許理論上可以讓加密的圖更清楚
.首先先從老師的blog下載S-Tools,執行後出現下圖畫面

再來將欲作為分享用圖片自桌面拖曳入S-Tools視窗中,然後如下圖所示 (附註:S-Tools圖片檔只吃.bmp跟.gif這兩種格式,音效檔則只吃.wav格式)

在來將欲隱藏在分享圖片中的資訊自桌面拖曳至分享圖片中,依此步驟執行將會出現如以下圖所示新對話窗要求你輸入加密密碼及隱藏格式

當步驟成立後,如下圖,Actions視窗將會出現正執行之編碼工作

編碼完成將開啟新的視窗,此視窗即為加密後的圖片影像

此時加密後的圖片在外觀上與原分享圖片無異,但在加密後的圖片上點右鍵在點取Rveal的選項會出現以下對話窗,此對話窗則是用來解密加密文件中的訊息所用,此時如果沒有正確的密碼或格式的話,將無法得到加密於其中的文件

如果解密正確則出現以下對話視窗,另存新檔後的檔案則為加密於其中的文件

結論:這軟體對於像我這種初學者來說藏文件是很方便沒錯,不過也如老師所說色盤會因為被修改後成為32個組群的色盤,對於竊取者或監視者而言很容易就被發現藏有額外文件的事實
Week 6: Index Embedded (I)
前言:
LSB的方法,需先將256色調色盤降為32色,
最後的調色盤可被分群為32個group,導致調色盤的不自然,使之容易被破解。
為了改善此缺點,於是有另外一派的研究希望嵌入資訊時,能夠不改變調色盤。
Index Embedded 就是其中一種不更改調色盤的方法。
以下文章描述Index Embedded 的方法,並在結尾提出結論與問題。
以圖一為例(下圖)
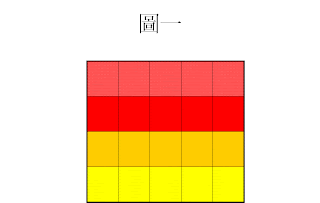
基於 GIF檔 有256種顏色,每張GIF 檔都有一個自己的調色盤。
換言之,不同的圖有不同的調色盤。
首先建立調色盤並且給予相對應的索引值。
第一個顏色給0,第二個顏色給1...依此類推。(圖二)
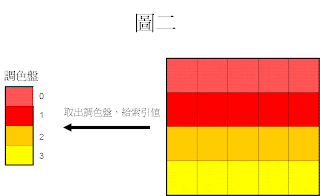
將調色盤,兩兩分組(Pair)。
Index 0 與 Index 1 為一組(Pair)
Index 2 與 Index 3 為一組(Pair)
並將原圖的像素對應到該像素的索引值(Index)(圖三)
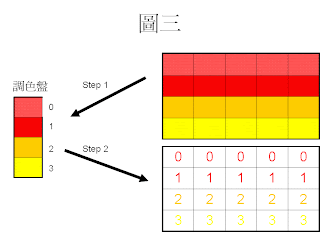
接著嵌入訊息至原圖中:
假若嵌入的資訊為 1010110 1010110
第 1 個bit 1 嵌入第 1 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 010110 1010110
第 2 個bit 0 嵌入第 2 個像素 0(Index值) , 0和0(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 10110 1010110
第 3 個bit 1 嵌入第 3 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 0110 1010110
第 4 個bit 0 嵌入第 4 個像素 0(Index值) , 0和0(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 110 1010110
第 5 個bit 1 嵌入第 5 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 10 1010110
第 6 個bit 1 嵌入第 6 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 0 1010110
第 7 個bit 0 嵌入第 7 個像素 1(Index值) , 0和1(Index值) 的LSB不相同,
該像素的 index 減1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 1010110
第 8 個bit 1 嵌入第 8 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 010110
第 9 個bit 0 嵌入第 9 個像素 1(Index值) , 0和1(Index值) 的LSB不相同,
該像素的 index 減1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 10110
第 10 個bit 1 嵌入第 10 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 0110
第 11 個bit 0 嵌入第 11 個像素 2(Index值) , 0 和 2 (Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 110
第 12 個bit 1 嵌入第 12 個像素 2(Index值) , 1 和 2 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair)變成 : 2 + 1 = 3(index值為3的顏色)
剩餘嵌入的資訊為 10
第 13 個bit 1 嵌入第 13 個像素 2(Index值) , 1 和 2 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair)變成 : 2 + 1 = 3(index值為3的顏色)
剩餘嵌入的資訊為 0
第 14 個bit 0 嵌入第 14 個像素 2(Index值) , 0 和 2 (Index值)的LSB相同,
該像素的 index 不變。
PS:上面的步驟是為了目前還不太懂的同學寫的,如果有疑問可以直接找我,
因為我有可能會有筆誤,或是哪裡觀念錯誤,請不吝指正,謝謝。
下圖為原圖與嵌入資訊後的圖片(偽裝媒體)
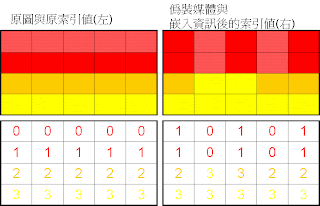
欲取出資訊時,直接取每個像素值的索引值的LSB即可得到隱藏訊息。
<<結論>>
與LSB比較起來,Index Embedded 的方式雖然不改變調色盤,
但是視覺(Visual)上容易察覺圖片可能會是偽裝媒體,
因為造成了顏色不協調的缺點。
在 week 6 看見鄭可欣同學的文章後,立刻與本泰討論顏色不協調的原因,
本泰認為調色盤應該需要經過排序,排序過後應該會使顏色看起來較為協調,
除此之外,Index Embedded 能夠嵌入的資訊量也比 LSB 方法 "少"。
LSB 的方法每個像素可以嵌入3bit,而Index Embedded 每個像素只能嵌入1 bit
除此之外,我提出一個問題是,當原本的圖片並非256色,而是255色時(或更少色時),
原先256色將會有128組pair,但255色將會有127組pair和一個"落單的顏色",
此時應該如何應對?
Week 7 將延續 Week 6 探討改進的方法
LSB的方法,需先將256色調色盤降為32色,
最後的調色盤可被分群為32個group,導致調色盤的不自然,使之容易被破解。
為了改善此缺點,於是有另外一派的研究希望嵌入資訊時,能夠不改變調色盤。
Index Embedded 就是其中一種不更改調色盤的方法。
以下文章描述Index Embedded 的方法,並在結尾提出結論與問題。
以圖一為例(下圖)

基於 GIF檔 有256種顏色,每張GIF 檔都有一個自己的調色盤。
換言之,不同的圖有不同的調色盤。
首先建立調色盤並且給予相對應的索引值。
第一個顏色給0,第二個顏色給1...依此類推。(圖二)

將調色盤,兩兩分組(Pair)。
Index 0 與 Index 1 為一組(Pair)
Index 2 與 Index 3 為一組(Pair)
並將原圖的像素對應到該像素的索引值(Index)(圖三)

接著嵌入訊息至原圖中:
假若嵌入的資訊為 1010110 1010110
第 1 個bit 1 嵌入第 1 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 010110 1010110
第 2 個bit 0 嵌入第 2 個像素 0(Index值) , 0和0(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 10110 1010110
第 3 個bit 1 嵌入第 3 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 0110 1010110
第 4 個bit 0 嵌入第 4 個像素 0(Index值) , 0和0(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 110 1010110
第 5 個bit 1 嵌入第 5 個像素 0(Index值) , 1和0 (Index值)的LSB不相同,
該像素的 index 加1。變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 10 1010110
第 6 個bit 1 嵌入第 6 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 0 1010110
第 7 個bit 0 嵌入第 7 個像素 1(Index值) , 0和1(Index值) 的LSB不相同,
該像素的 index 減1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 1010110
第 8 個bit 1 嵌入第 8 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 010110
第 9 個bit 0 嵌入第 9 個像素 1(Index值) , 0和1(Index值) 的LSB不相同,
該像素的 index 減1。(找該Index的Pair) 變成 : 0 + 1 = 1(index值為1的顏色)
剩餘嵌入的資訊為 10110
第 10 個bit 1 嵌入第 10 個像素 1(Index值) , 1和1(Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 0110
第 11 個bit 0 嵌入第 11 個像素 2(Index值) , 0 和 2 (Index值)的LSB相同,
該像素的 index 不變。
剩餘嵌入的資訊為 110
第 12 個bit 1 嵌入第 12 個像素 2(Index值) , 1 和 2 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair)變成 : 2 + 1 = 3(index值為3的顏色)
剩餘嵌入的資訊為 10
第 13 個bit 1 嵌入第 13 個像素 2(Index值) , 1 和 2 (Index值)的LSB不相同,
該像素的 index 加1。(找該Index的Pair)變成 : 2 + 1 = 3(index值為3的顏色)
剩餘嵌入的資訊為 0
第 14 個bit 0 嵌入第 14 個像素 2(Index值) , 0 和 2 (Index值)的LSB相同,
該像素的 index 不變。
PS:上面的步驟是為了目前還不太懂的同學寫的,如果有疑問可以直接找我,
因為我有可能會有筆誤,或是哪裡觀念錯誤,請不吝指正,謝謝。
下圖為原圖與嵌入資訊後的圖片(偽裝媒體)

欲取出資訊時,直接取每個像素值的索引值的LSB即可得到隱藏訊息。
<<結論>>
與LSB比較起來,Index Embedded 的方式雖然不改變調色盤,
但是視覺(Visual)上容易察覺圖片可能會是偽裝媒體,
因為造成了顏色不協調的缺點。
在 week 6 看見鄭可欣同學的文章後,立刻與本泰討論顏色不協調的原因,
本泰認為調色盤應該需要經過排序,排序過後應該會使顏色看起來較為協調,
除此之外,Index Embedded 能夠嵌入的資訊量也比 LSB 方法 "少"。
LSB 的方法每個像素可以嵌入3bit,而Index Embedded 每個像素只能嵌入1 bit
除此之外,我提出一個問題是,當原本的圖片並非256色,而是255色時(或更少色時),
原先256色將會有128組pair,但255色將會有127組pair和一個"落單的顏色",
此時應該如何應對?
Week 7 將延續 Week 6 探討改進的方法
Week 8: Index Embedded (III)
在 Week8 的課堂上,我們討論了排序調色盤的方法
本泰用了一種排序方法 r*653356+g*256+b
而老師提供了另外一種以亮度為主的排序方法
但屏除這兩種方式外,老師說還有可以改善的空間。
以我的認知,若是把焦點放在調色盤上,又不希望更動調色盤原來的顏色,
改進的重點應該是調色盤經過大風吹後的新位置。
看了一些同學們作的實驗,不管是以亮度排序或是以r*653356+g*256+b 排序
都沒辦法做到相似的擺在一起。
我認為調色盤的安排,應該要讓越相似的顏色,越放在一起。
而不是用某種鍵值來排序。
應該用分群,而非排序。
讓顏色相似的成群。
而分群的維度,在我的想法中除了算兩個像素(R,G,B)的距離值外
或許可以增加第四個維度"亮度"當作參考維度,即(R,G,B,亮度)。
直覺上應該是用分群,讓顏色相似成群,而非排序。
本泰用了一種排序方法 r*653356+g*256+b
而老師提供了另外一種以亮度為主的排序方法
但屏除這兩種方式外,老師說還有可以改善的空間。
以我的認知,若是把焦點放在調色盤上,又不希望更動調色盤原來的顏色,
改進的重點應該是調色盤經過大風吹後的新位置。
看了一些同學們作的實驗,不管是以亮度排序或是以r*653356+g*256+b 排序
都沒辦法做到相似的擺在一起。
我認為調色盤的安排,應該要讓越相似的顏色,越放在一起。
而不是用某種鍵值來排序。
應該用分群,而非排序。
讓顏色相似的成群。
而分群的維度,在我的想法中除了算兩個像素(R,G,B)的距離值外
或許可以增加第四個維度"亮度"當作參考維度,即(R,G,B,亮度)。
直覺上應該是用分群,讓顏色相似成群,而非排序。
week8筆記
gif檔的調色盤會將所有有用到的顏色放取出來
我們將顏色給一個index的值(gif檔最多只有256色,所以index值最大只到256)
如果我們要隱藏的資訊為010011
我們先取出要隱藏的index(那個index是亂數取嗎???)
例如取出的index為10 18 36 42 60 73
我們將取出的index轉成二進位之後,再將所要隱藏的資訊隱藏在二進位的最後一個數字
index 10 18 36 42 60 73
二進位 1100 10010 100100 101010 111100 1001001
隱藏後的二進位 1100 10011 100100 101010 111101 1001001
index變成10 19 36 42 61 73
將index=18的顏色改成index=19的顏色
將index=60的顏色改成index=61的顏色
如果要將所隱藏的資訊取出來的話,我們必須先知道index的值為多少
但是要如何把index的值讓對方知道又是一個問題
以上此種方法不適合用在bmp檔,因為bmp檔的調色盤沒有限制
如果調色盤被改變,index也會被改變
但是gif檔的調色盤看起來是亂亂的
隱藏後的圖看起來有很大的瑕疵
所以解決方法是將調色盤先依照亮度排序
然後再按照原先的方法進行隱藏
隱藏後的圖看起來就好多了
我們將顏色給一個index的值(gif檔最多只有256色,所以index值最大只到256)
如果我們要隱藏的資訊為010011
我們先取出要隱藏的index(那個index是亂數取嗎???)
例如取出的index為10 18 36 42 60 73
我們將取出的index轉成二進位之後,再將所要隱藏的資訊隱藏在二進位的最後一個數字
index 10 18 36 42 60 73
二進位 1100 10010 100100 101010 111100 1001001
隱藏後的二進位 1100 10011 100100 101010 111101 1001001
index變成10 19 36 42 61 73
將index=18的顏色改成index=19的顏色
將index=60的顏色改成index=61的顏色
如果要將所隱藏的資訊取出來的話,我們必須先知道index的值為多少
但是要如何把index的值讓對方知道又是一個問題
以上此種方法不適合用在bmp檔,因為bmp檔的調色盤沒有限制
如果調色盤被改變,index也會被改變
但是gif檔的調色盤看起來是亂亂的
隱藏後的圖看起來有很大的瑕疵
所以解決方法是將調色盤先依照亮度排序
然後再按照原先的方法進行隱藏
隱藏後的圖看起來就好多了
Week 5 : 如何判斷一張雜亂的圖 (續)
Week4 老師提到一個利用機率的方式,
測試一張圖是否為亂亂的圖。
這個方法的中心思想是 "相鄰兩像素間,同色與不同色的比例應相等"
那我根據這個中心思想作下列的實驗:
圖一為一張規律的圖片:黑白相間的圖
我們首先從圖一開始分析。
圖一:
黑色右邊是白色佔 10 次,(計算方法請看圖一(續),上圖)
依此類推,白色右邊是黑色佔 10 次,
白色旁邊是白色佔 0 次,黑色旁邊是黑色佔 0 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(10 + 10) : ( 0 + 0 ) = 20 : 0
比例非常的不均,並非接近1:1,所以認定該圖為一張規律的圖。
接著我們討論圖二(如下):一行黑色一行白色(規律)
圖二:
黑色右邊是白色佔 10 次,
白色右邊是黑色佔 10 次,
白色旁邊是白色佔 0 次,黑色旁邊是黑色佔 0 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(10 + 10) : (0+0) = 20 : 0
比例不均,並非接近1:1,認定該圖為一張規律的圖。
接著討論圖三(下圖):左邊是白色,右邊是黑色(規律)
圖三:
黑色右邊是白色佔 0 次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 7 次,黑色旁邊是黑色佔 8 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(0 + 5) : (7+8) = 5 : 15 = 1 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖四:
圖四:
黑色右邊是白色佔 4 次,
白色右邊是黑色佔 4 次,
白色旁邊是白色佔 8 次,黑色旁邊是黑色佔 4 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(4 + 4) : (8+4) = 8 : 12 = 2 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖五:
圖五
黑色右邊是白色佔 2 次,
白色右邊是黑色佔 3 次,
白色旁邊是白色佔 5 次,黑色旁邊是黑色佔 10 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(2 + 3) : 5+10) = 5 : 15 = 1 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖六:不規律的圖
圖一至圖五討論了幾種規律的圖形樣式
圖六討論不規則的圖形樣式
黑色右邊是白色佔 6次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 4 次,黑色旁邊是黑色佔 5 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(6 + 5) : (5+4) = 11 : 9
很接近1:1,認定該圖為一張亂亂的圖。
雖然圖一至圖六,依照此法能夠得判斷該圖是否為雜亂
現在討論圖七(對稱圖形)
黑色右邊是白色佔 5次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 6 次,黑色旁邊是黑色佔 4 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(5 + 5) : ( 6 + 4 ) = 10 : 10
很接近1:1,依照此法則認定該圖為一張亂亂的圖。
但事實上這張圖我認為是規律的圖,因為這張圖是一張上下對稱的圖形。
結論:
我認為此法無法判斷所有的情況。
測試一張圖是否為亂亂的圖。
這個方法的中心思想是 "相鄰兩像素間,同色與不同色的比例應相等"
那我根據這個中心思想作下列的實驗:
圖一為一張規律的圖片:黑白相間的圖

我們首先從圖一開始分析。

圖一:
黑色右邊是白色佔 10 次,(計算方法請看圖一(續),上圖)
依此類推,白色右邊是黑色佔 10 次,
白色旁邊是白色佔 0 次,黑色旁邊是黑色佔 0 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(10 + 10) : ( 0 + 0 ) = 20 : 0
比例非常的不均,並非接近1:1,所以認定該圖為一張規律的圖。
接著我們討論圖二(如下):一行黑色一行白色(規律)

圖二:
黑色右邊是白色佔 10 次,
白色右邊是黑色佔 10 次,
白色旁邊是白色佔 0 次,黑色旁邊是黑色佔 0 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(10 + 10) : (0+0) = 20 : 0
比例不均,並非接近1:1,認定該圖為一張規律的圖。
接著討論圖三(下圖):左邊是白色,右邊是黑色(規律)

圖三:
黑色右邊是白色佔 0 次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 7 次,黑色旁邊是黑色佔 8 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(0 + 5) : (7+8) = 5 : 15 = 1 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖四:

圖四:
黑色右邊是白色佔 4 次,
白色右邊是黑色佔 4 次,
白色旁邊是白色佔 8 次,黑色旁邊是黑色佔 4 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(4 + 4) : (8+4) = 8 : 12 = 2 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖五:

圖五
黑色右邊是白色佔 2 次,
白色右邊是黑色佔 3 次,
白色旁邊是白色佔 5 次,黑色旁邊是黑色佔 10 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(2 + 3) : 5+10) = 5 : 15 = 1 : 3
比例不均,並非接近1:1,認定該圖為一張規律的圖。
討論圖六:不規律的圖

圖一至圖五討論了幾種規律的圖形樣式
圖六討論不規則的圖形樣式
黑色右邊是白色佔 6次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 4 次,黑色旁邊是黑色佔 5 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(6 + 5) : (5+4) = 11 : 9
很接近1:1,認定該圖為一張亂亂的圖。
雖然圖一至圖六,依照此法能夠得判斷該圖是否為雜亂
現在討論圖七(對稱圖形)

黑色右邊是白色佔 5次,
白色右邊是黑色佔 5 次,
白色旁邊是白色佔 6 次,黑色旁邊是黑色佔 4 次,
相鄰顏色相同 與 相鄰顏色不同的比例為
(5 + 5) : ( 6 + 4 ) = 10 : 10
很接近1:1,依照此法則認定該圖為一張亂亂的圖。
但事實上這張圖我認為是規律的圖,因為這張圖是一張上下對稱的圖形。
結論:
我認為此法無法判斷所有的情況。
訂閱:
意見 (Atom)